
Dans ce tutoriel, Vous apprendrez la régression logistique. Ici, vous saurez ce qu’est exactement la régression logistique et vous verrez également un exemple avec Python. La régression logistique est un sujet important de l’apprentissage automatique et je vais essayer de le rendre aussi simple que possible.
Au début du XXe siècle, la régression logistique était principalement utilisée en biologie après cela, elle a été utilisée dans certaines applications des sciences sociales. Si vous êtes curieux, Vous pouvez demander où nous devrions utiliser la régression logistique? Nous utilisons donc la régression logistique lorsque notre variable indépendante est catégorique.
Exemples:
- Pour prédire si une personne achètera une voiture (1) ou (0)
- Pour savoir si la tumeur est maligne (1) ou (0)
Considérons maintenant un scénario où vous devez classer si une personne achètera une voiture ou non. Dans ce cas, si nous utilisons une régression linéaire simple, nous devrons spécifier un seuil sur lequel la classification peut être effectuée.
Disons que la classe réelle est la personne qui achètera la voiture, et la valeur continue prévue est de 0,45 et le seuil que nous avons considéré est de 0.5, alors ce point de données sera considéré comme la personne n’achètera pas la voiture et cela conduira à la mauvaise prédiction.
Nous concluons donc que nous ne pouvons pas utiliser la régression linéaire pour ce type de problème de classification. Comme nous savons que la régression linéaire est bornée, Voici donc la régression logistique où la valeur varie strictement de 0 à 1.
Régression logistique simple:
Sortie: 0 ou 1
Hypothèse: K= W *X +B
hΘ(x) =sigmoïde(K)
Fonction sigmoïde:


Types de régression logistique:
Régression logistique binaire
Seulement deux résultats possibles (Catégorie).
Exemple: La personne achètera une voiture ou non.
Régression logistique multinomiale
Plus de deux catégories possibles sans ordre.
Régression logistique ordinale
Plus de deux catégories possibles avec l’ordre.
Exemple réel avec Python:
Maintenant, nous allons résoudre un problème réel avec la régression logistique. Nous avons un ensemble de données ayant 5 colonnes à savoir: ID utilisateur, Sexe, Âge, Estimé et Acheté. Nous devons maintenant construire un modèle capable de prédire si, sur le paramètre donné, une personne achètera ou non une voiture.
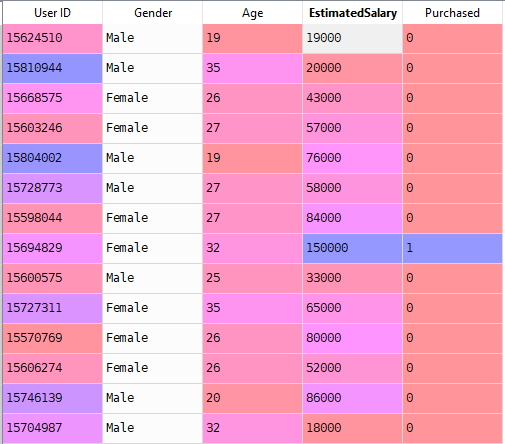
Étapes pour Construire le modèle:
1. Importing the libraries
Ici, nous importerons les bibliothèques qui seront nécessaires pour construire le modèle.
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd2. Importing the Data set
Nous importerons notre jeu de données dans une variable (c’est-à-dire un jeu de données) à l’aide de pandas.
dataset = pd.read_csv('Social_Network_Ads.csv')3. Splitting our Data set in Dependent and Independent variables.
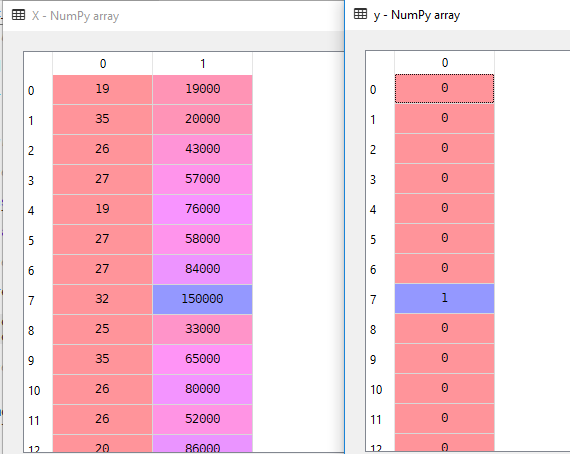
Dans notre ensemble de données, nous considérerons l’Âge et EstimatedSalary comme une variable indépendante et Acheté comme une Variable dépendante.
X = dataset.iloc].valuesy = dataset.iloc.valuesIci X est une variable indépendante et y est une variable dépendante.
3. Splitting the Data set into the Training Set and Test Set
Maintenant, nous allons diviser notre ensemble de Données en Données d’entraînement et en Données de test. Les données de formation seront utilisées pour former notre modèle logistique et les données de test seront utilisées pour valider notre modèle. Nous utiliserons Sklearn pour diviser nos données. Nous importerons train_test_split depuis sklearn.model_selection
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
4. Feature Scaling
Maintenant, nous allons mettre à l’échelle nos données entre 0 et 1 pour obtenir une meilleure précision.
Ici, la mise à l’échelle est importante car il y a une énorme différence entre l’âge et le salaire estimé.
- Importez StandardScaler depuis sklearn.prétraitement
- Puis créez une instance sc_X de l’objet StandardScaler
- Puis ajustez et transformez X_train et transformez X_test
from sklearn.preprocessing import StandardScalersc_X = StandardScaler()X_train = sc_X.fit_transform(X_train)X_test = sc_X.transform(X_test)
5. Fitting Logistic Regression to the Training Set
Maintenant, nous allons construire notre classificateur (logistique).
- Import LogisticRegression depuis sklearn.linear_model
- Crée un classificateur d’instance de l’objet LogisticRegression et donne
random_state=0 pour obtenir le même résultat à chaque fois. - Maintenant, utilisez ce classificateur pour adapter X_train et y_train
from sklearn.linear_model import LogisticRegressionclassifier = LogisticRegression(random_state=0)classifier.fit(X_train, y_train)Santé!! Après avoir exécuté la commande ci-dessus, vous aurez un classificateur qui peut prédire si une personne achètera une voiture ou non.
Utilisez maintenant le classificateur pour faire la prédiction de l’ensemble de données de test et trouvez la précision à l’aide de la matrice de confusion.
6. Predicting the Test set results
y_pred = classifier.predict(X_test)Maintenant, nous allons obtenir y_pred

Maintenant, nous pouvons utiliser y_test (Résultat réel) et y_pred (Résultat prédit) pour obtenir la précision de notre modèle.
7. Making the Confusion Matrix
En utilisant la matrice de confusion, nous pouvons obtenir la précision de notre modèle.
from sklearn.metrics import confusion_matrixcm = confusion_matrix(y_test, y_pred)Vous obtiendrez une matrice cm.

Utilisez cm pour calculer la précision comme indiqué ci-dessous:
Précision=(cm + cm) /(Points de données de test totaux)

Nous obtenons ici une précision de 89%. À votre santé!! nous obtenons une bonne précision.
Enfin, nous visualiserons le résultat de notre set d’entraînement et le résultat de notre set de test. Nous utiliserons matplotlib pour tracer notre ensemble de données.
Visualisation du résultat de l’Ensemble de formation
from matplotlib.colors import ListedColormapX_set, y_set = X_train, y_trainX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Training set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()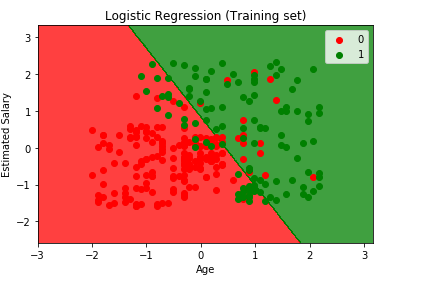
Visualisation du résultat de l’ensemble de test
from matplotlib.colors import ListedColormapX_set, y_set = X_test, y_testX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Test set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()
Vous pouvez maintenant créer votre propre classificateur pour la régression logistique.
Merci!! Continuez à Coder!!
Remarque: Ceci est un article invité, et l’opinion dans cet article est de l’auteur invité. Si vous avez des problèmes avec l »un des articles publiés sur www.poste de marktech.com please contact at [email protected]
Advertisement
