Tous les utilisateurs de base de données connaissent les fonctions d’agrégation régulières qui fonctionnent sur une table entière et sont utilisées avec une clause GROUP BY. Mais très peu de gens utilisent les fonctions de fenêtre en SQL. Ceux-ci fonctionnent sur un ensemble de lignes et renvoient une seule valeur agrégée pour chaque ligne.
Le principal avantage de l’utilisation des fonctions de fenêtre par rapport aux fonctions d’agrégat régulières est: Les fonctions de fenêtre ne regroupent pas les lignes en une seule ligne de sortie, les lignes conservent leurs identités distinctes et une valeur agrégée est ajoutée à chaque ligne.
Jetons un coup d’œil au fonctionnement des fonctions de fenêtre, puis voyons quelques exemples d’utilisation pratique pour être sûr que les choses sont claires et aussi comment le SQL et la sortie se comparent à ceux des fonctions SUM().
Comme toujours, assurez-vous d’être entièrement sauvegardé, surtout si vous essayez de nouvelles choses avec votre base de données.
Introduction aux fonctions de fenêtre
Les fonctions de fenêtre fonctionnent sur un ensemble de lignes et renvoient une seule valeur agrégée pour chaque ligne. Le terme Fenêtre décrit l’ensemble de lignes de la base de données sur lesquelles la fonction fonctionnera.
Nous définissons la fenêtre (ensemble de lignes sur lesquelles les fonctions fonctionnent) à l’aide d’une clause OVER(). Nous discuterons plus en détail de la clause OVER() dans l’article ci-dessous.
Types of Window functions
Syntax
|
1
2
3
4
|
window_function ( expression )
OVER ( )
|
Arguments
window_function
Specify the name of the window function
ALL
ALL is an optional keyword. Lorsque vous inclurez TOUT, toutes les valeurs seront comptées, y compris les valeurs en double. DISTINCT n’est pas pris en charge dans les fonctions de fenêtre
expression
La colonne ou l’expression cible sur laquelle les fonctions fonctionnent. En d’autres termes, le nom de la colonne pour laquelle nous avons besoin d’une valeur agrégée. Par exemple, une colonne contenant le montant de la commande afin que nous puissions voir le total des commandes reçues.
SUR
Spécifie les clauses de fenêtre pour les fonctions d’agrégation.
PARTITION BY partition_list
Définit la fenêtre (ensemble de lignes sur lesquelles la fonction de fenêtre fonctionne) pour les fonctions de fenêtre. Nous devons fournir un champ ou une liste de champs pour la clause partition après PARTITION PAR. Plusieurs champs doivent être séparés par une virgule comme d’habitude. Si la PARTITION BY n’est pas spécifiée, le regroupement sera effectué sur toute la table et les valeurs seront agrégées en conséquence.
ORDER BY order_list
Trie les lignes de chaque partition. Si ORDER BY n’est pas spécifié, ORDER BY utilise la table entière.
Exemples
Créons une table et insérons des enregistrements factices pour écrire d’autres requêtes. Exécutez ci-dessous le code.
Fonctions de fenêtre d’agrégation
SUM()
Nous connaissons tous la fonction d’agrégation SUM(). Il fait la somme du champ spécifié pour le groupe spécifié (comme la ville, l’état, le pays, etc.) ou pour la table entière si group n’est pas spécifié. Nous verrons quelle sera la sortie de la fonction d’agrégation SUM() régulière et de la fonction d’agrégation SUM() de fenêtre.
Voici un exemple de fonction d’agrégat SOMME() régulière. Il additionne le montant de la commande pour chaque ville.
Vous pouvez voir dans le jeu de résultats qu’une fonction d’agrégation régulière regroupe plusieurs lignes en une seule ligne de sortie, ce qui fait perdre leur identité à des lignes individuelles.
|
1
2
3
4
|
SÉLECTIONNEZ la ville, LA SOMME (order_amount) total_order_amount
DE. GROUPE PAR ville
|

Cela n’arrive pas avec les fonctions d’agrégation de fenêtres. Les lignes conservent leur identité et affichent également une valeur agrégée pour chaque ligne. Dans l’exemple ci-dessous, la requête fait la même chose, à savoir qu’elle agrège les données de chaque ville et affiche la somme du montant total de la commande pour chacune d’elles. Cependant, la requête insère maintenant une autre colonne pour le montant total de la commande afin que chaque ligne conserve son identité. La colonne marquée grand_total est la nouvelle colonne de l’exemple ci-dessous.
AVG()
AVG ou Average fonctionne exactement de la même manière avec une fonction de fenêtre.
La requête suivante vous donnera le montant moyen de la commande pour chaque ville et pour chaque mois (bien que pour simplifier, nous n’ayons utilisé les données qu’un mois).
Nous spécifions plus d’une moyenne en spécifiant plusieurs champs dans la liste des partitions.
Il convient également de noter que vous pouvez utiliser des expressions dans les listes comme MONTH(order_date) comme indiqué dans la requête ci-dessous. Comme toujours, vous pouvez rendre ces expressions aussi complexes que vous le souhaitez tant que la syntaxe est correcte!
Sur l’image ci-dessus, nous pouvons clairement voir qu’en moyenne, nous avons reçu des commandes de 12 333 pour la ville d’Arlington pour avril 2017.
Montant Moyen de la Commande = Montant Total de la Commande / Total des Commandes
= (20,000 + 15,000 + 2,000) / 3
=12,333
Vous pouvez également utiliser la combinaison de la fonction SUM()& COUNT() pour calculer une moyenne.
MIN()
La fonction d’agrégation MIN() trouvera la valeur minimale pour un groupe spécifié ou pour la table entière si group n’est pas spécifié.
Par exemple, nous recherchons le plus petit ordre (ordre minimum) pour chaque ville que nous utiliserions la requête suivante.
MAX()
Tout comme les fonctions MIN() vous donnent la valeur minimale, la fonction MAX() identifiera la plus grande valeur d’un champ spécifié pour un groupe de lignes spécifié ou pour la table entière si un groupe n’est pas spécifié.
trouvons la plus grosse commande (montant maximum de la commande) pour chaque ville.
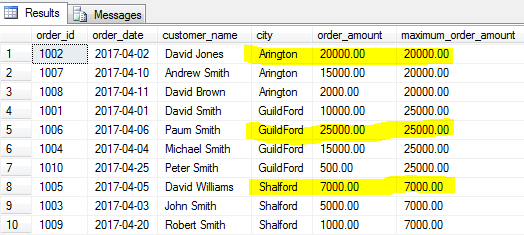
COUNT()
La fonction COUNT() comptera les enregistrements/lignes.
Notez que DISTINCT n’est pas pris en charge avec la fonction window COUNT() alors qu’il est pris en charge pour la fonction regular COUNT(). DISTINCT vous aide à trouver les valeurs distinctes d’un champ spécifié.
Par exemple, si nous voulons voir combien de clients ont passé une commande en avril 2017, nous ne pouvons pas compter directement tous les clients. Il est possible qu’un même client ait passé plusieurs commandes dans le même mois.
COUNT(customer_name) vous donnera un résultat incorrect car il comptera les doublons. Alors que COUNT(DISTINCT customer_name) vous donnera le résultat correct car il ne compte chaque client unique qu’une seule fois.
Valide pour la fonction COUNT() régulière:
|
1
2
3
4
5
|
SÉLECTIONNEZ la ville, COMPTEZ (nom de client DISTINCT) number_of_customers
DE.
GROUPE PAR ville
|
Invalide pour la fonction window COUNT():
La requête ci-dessus avec la fonction Window vous donnera l’erreur ci-dessous.
Maintenant, trouvons l’ordre total reçu pour chaque ville en utilisant la fonction window COUNT().
Fonctions de fenêtre de classement
Tout comme les fonctions d’agrégation de fenêtre agrègent la valeur d’un champ spécifié, les fonctions de CLASSEMENT classent les valeurs d’un champ spécifié et les classent en fonction de leur rang.
L’utilisation la plus courante des fonctions de CLASSEMENT consiste à trouver les enregistrements top(N) en fonction d’une certaine valeur. Par exemple, les 10 employés les mieux payés, les 10 étudiants les mieux classés, les 50 commandes les plus importantes, etc.
Les fonctions de CLASSEMENT suivantes sont prises en charge :
RANK(), DENSE_RANK(), ROW_NUMBER(), NTILE()
Discutons-en une par une.
RANK()
La fonction RANK() est utilisée pour donner un rang unique à chaque enregistrement en fonction d’une valeur spécifiée, par exemple le salaire, le montant de la commande, etc.
Si deux enregistrements ont la même valeur, la fonction RANK() attribuera le même rang aux deux enregistrements en sautant le rang suivant. Cela signifie que s’il y a deux valeurs identiques au rang 2, il affectera le même rang 2 aux deux enregistrements, puis sautera le rang 3 et affectera le rang 4 à l’enregistrement suivant.
Classons chaque commande par son montant.
|
1
2
3
4
5
|
SELECT order_id, order_date, customer_name, city,
RANK()OVER(ORDER BY order_amount DESC)
div> DE.
|
À partir de l’image ci-dessus, vous pouvez voir que le même rang (3) est attribué à deux enregistrements identiques (chacun ayant un montant de commande de 15 000 ) et il saute ensuite le rang suivant (4) et attribue le rang 5 à l’enregistrement suivant.
DENSE_RANK()
La fonction DENSE_RANK() est identique à la fonction RANK() sauf qu’elle ne saute aucun rang. Cela signifie que si deux enregistrements identiques sont trouvés, DENSE_RANK() affectera le même rang aux deux enregistrements mais ne sautera pas puis ignorera le rang suivant.
Voyons comment cela fonctionne dans la pratique.
Comme vous pouvez le voir clairement ci-dessus, le même rang est donné à deux enregistrements identiques (ayant chacun le même montant de commande), puis le numéro de rang suivant est donné à l’enregistrement suivant sans sauter de valeur de rang.
ROW_NUMBER()
Le nom est explicite. Ces fonctions attribuent un numéro de ligne unique à chaque enregistrement.
Le numéro de ligne sera réinitialisé pour chaque partition si PARTITION BY est spécifiée. Voyons comment ROW_NUMBER() fonctionne sans PARTITION BY puis avec PARTITION BY.
ROW_ NUMBER() sans PARTITION PAR
ROW_NUMBER() avec PARTITION PAR
Notez que nous avons fait la partition sur city. Cela signifie que le numéro de ligne est réinitialisé pour chaque ville et redémarre donc à 1. Cependant, l’ordre des lignes est déterminé par le montant de la commande de sorte que pour une ville donnée, le montant de la commande le plus important sera la première ligne et le numéro de ligne 1 ainsi attribué.
NTILE()
NTILE() est une fonction de fenêtre très utile. Il vous aide à identifier dans quel centile (ou quartile, ou toute autre subdivision) une ligne donnée tombe.
Cela signifie que si vous avez 100 lignes et que vous souhaitez créer 4 quartiles en fonction d’un champ de valeur spécifié, vous pouvez le faire facilement et voir combien de lignes tombent dans chaque quartile.
Voyons un exemple. Dans la requête ci-dessous, nous avons spécifié que nous voulons créer quatre quartiles en fonction du montant de la commande. Nous voulons ensuite voir combien d’ordres tombent dans chaque quartile.
NTILE crée des tuiles basées sur la formule suivante:
No de lignes dans chaque tuile = nombre de lignes dans le jeu de résultats / nombre de tuiles spécifiées
Voici notre exemple, nous avons un total de 10 lignes et 4 tuiles sont spécifiées dans la requête, donc le nombre de lignes dans chaque tuile sera de 2,5 (10/4). Comme le nombre de lignes doit être un nombre entier, pas une décimale. Le moteur SQL affectera 3 lignes pour les deux premiers groupes et 2 lignes pour les deux groupes restants.
Fonctions de fenêtre de valeur
LAG() et LEAD()
Les fonctions LEAD() et LAG() sont très puissantes mais peuvent être complexes à expliquer.
Comme il s’agit d’un article introductif ci-dessous, nous examinons un exemple très simple pour illustrer comment les utiliser.
La fonction LAG permet d’accéder aux données de la ligne précédente dans le même jeu de résultats sans utiliser de jointures SQL. Vous pouvez voir dans l’exemple ci-dessous, en utilisant la fonction de DÉCALAGE, nous avons trouvé la date de commande précédente.
Script pour trouver la date de commande précédente en utilisant la fonction LAG():
La fonction LEAD permet d’accéder aux données de la ligne suivante dans le même jeu de résultats sans utiliser de jointures SQL. Vous pouvez voir dans l’exemple ci-dessous, en utilisant la fonction LEAD, nous avons trouvé la prochaine date de commande.
Script pour trouver la date de commande suivante à l’aide de la fonction LEAD():
FIRST_VALUE() et LAST_VALUE()
Ces fonctions vous aident à identifier le premier et le dernier enregistrement dans une partition ou une table entière si la PARTITION BY n’est pas spécifiée.
Trouvons le premier et le dernier ordre de chaque ville à partir de notre jeu de données existant. Remarque La clause ORDER BY est obligatoire pour les fonctions FIRST_VALUE() et LAST_VALUE()
De l’image ci-dessus, nous pouvons clairement voir que la première commande reçue le 02/04/2017 et la dernière commande reçue le 11/04/2017 pour la ville d’Arlington et cela fonctionne de la même manière pour les autres villes.
Liens utiles
- Types de sauvegarde &Stratégies pour les bases de données SQL
- Article TechNet sur la clause OVER
- Article MSDN Sur DENSE_RANK
Autres articles intéressants de Ben
Comment SQL Server sélectionne une victime de blocage
Comment Utilisez les fonctions de fenêtre
- Auteur
- Messages récents
Voir tous les articles de Ben Richardson
- Power BI: Graphiques en cascade et Visuels combinés – 19 janvier 2021
- Power BI: Mise en forme conditionnelle et couleurs des données en action – 14 janvier 2021
- Power BI : Importation de données depuis SQL Server et MySQL – 12 janvier 2021