
twitter linkedin reddit i denne opplæringen vil du lære logistisk regresjon. Her vet du hva Som Er Logistisk Regresjon, og du vil også se Et Eksempel med Python. Logistisk Regresjon er et viktig Tema For Maskinlæring, og jeg vil prøve å gjøre Det så enkelt som mulig.I begynnelsen av det tjuende århundre Ble Logistisk regresjon hovedsakelig brukt i Biologi etter dette, den ble brukt i noen samfunnsvitenskapelige applikasjoner. Hvis du er nysgjerrig, kan du spørre hvor vi skal bruke logistisk regresjon? Så vi bruker Logistisk Regresjon når vår uavhengige variabel er kategorisk.
Eksempler:
- for å forutsi om en person vil kjøpe en bil (1) eller (0)
- for å vite om svulsten er ondartet (1) eller (0)
la Oss nå vurdere et scenario der du må klassifisere om en person vil kjøpe en bil eller ikke. I dette tilfellet, hvis vi bruker enkel lineær regresjon, må vi spesifisere en terskel som klassifisering kan gjøres på.La oss si at den faktiske klassen er personen vil kjøpe bilen, og spådd kontinuerlig verdi er 0,45 og terskelen vi har vurdert er 0.5, da vil dette datapunktet bli vurdert som personen ikke vil kjøpe bilen, og dette vil føre til feil prediksjon.
så vi konkluderer med at vi ikke kan bruke lineær regresjon for denne typen klassifiseringsproblem. Som vi vet lineær regresjon er begrenset, så her kommer logistisk regresjon hvor verdien strengt varierer fra 0 til 1.
Enkel Logistisk Regresjon:
Utgang: 0 Eller 1
Hypotese: K = W * X + B
hΘ(x) = sigmoid(K)
Sigmoid Funksjon:


Typer Logistisk Regresjon:
Binær Logistisk Regresjon
Bare to mulige utfall(Kategori).
Eksempel: personen vil kjøpe en bil eller ikke.
Multinomial Logistisk Regresjon
Mer enn to Kategorier mulig uten bestilling.
Ordinær Logistisk Regresjon
Mer enn to Kategorier mulig med bestilling.
Real-World Eksempel Med Python:
nå løser Vi et reelt problem med Logistisk Regresjon. Vi har Et datasett med 5 kolonner nemlig: Bruker-ID, Kjønn, Alder, EstimatedSalary og Kjøpt. Nå må vi bygge en modell som kan forutsi om en person vil kjøpe en bil eller ikke på den angitte parameteren.
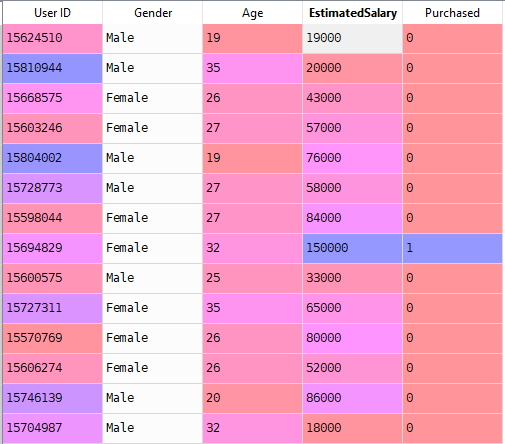
Trinn For Å Bygge Modellen:
1. Importing the libraries
her importerer vi biblioteker som trengs for å bygge modellen.
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd2. Importing the Data set
vi importerer datasettet vårt i en variabel (dvs.datasett) ved hjelp av pandaer.
dataset = pd.read_csv('Social_Network_Ads.csv')3. Splitting our Data set in Dependent and Independent variables.
i vårt datasett vurderer vi alder og estimatetsalary som uavhengig variabel og kjøpt som avhengig variabel.
X = dataset.iloc].valuesy = dataset.iloc.valuesHer Er X Uavhengig variabel og y Er Avhengig variabel.
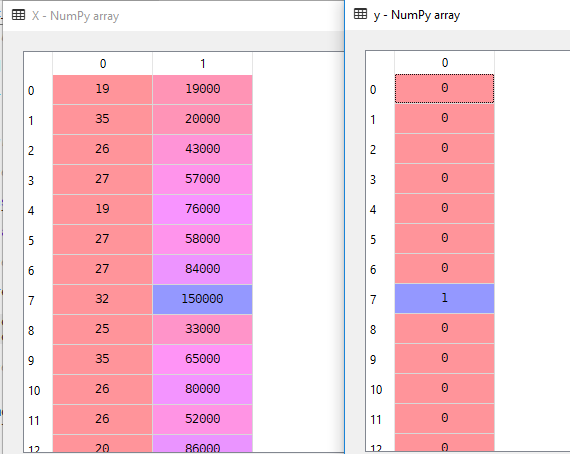
3. Splitting the Data set into the Training Set and Test Set
nå deler Vi datasettet vårt i Treningsdata og Testdata. Treningsdata vil bli brukt til å trene Vår Logistikkmodell og Testdata vil bli brukt til å validere vår modell. Vi bruker Sklearn til å dele dataene våre. Vi importerer train_test_split fra sklearn.model_selection
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
4. Feature Scaling
nå skal vi gjøre funksjonsskalering for å skalere dataene våre mellom 0 og 1 for å få bedre nøyaktighet.
Her Skalering er viktig fordi det er en stor forskjell Mellom Alder og EstimatedSalay.
- Importer StandardScaler fra sklearn.forbehandling
- deretter lage en forekomst sc_X av objektet StandardScaler
- deretter tilpasse Og transformere X_train Og transformere X_test
from sklearn.preprocessing import StandardScalersc_X = StandardScaler()X_train = sc_X.fit_transform(X_train)X_test = sc_X.transform(X_test)
5. Fitting Logistic Regression to the Training Set
nå skal vi bygge vår klassifikator (logistikk).
- Importer Logistikkregresjon fra sklearn.linear_model
- Lag en instans klassifiserer av objektet LogisticRegression og gi
random_state = 0 for å få samme resultat hver gang. - bruk nå denne klassifikatoren Til å passe X_train og y_train
from sklearn.linear_model import LogisticRegressionclassifier = LogisticRegression(random_state=0)classifier.fit(X_train, y_train)Skål!! Etter å ha utført kommandoen ovenfor, har du en klassifikator som kan forutsi om en person vil kjøpe en bil eller ikke.
bruk nå klassifikatoren til å gjøre prediksjonen For Testdatasettet og finne nøyaktigheten ved Hjelp Av Forvirringsmatrise.
6. Predicting the Test set results
y_pred = classifier.predict(X_test)nå får vi y_pred

nå kan vi bruke y_test (faktisk resultat) og y_pred ( spådd resultat) for å få nøyaktigheten av vår modell.
7. Making the Confusion Matrix
Ved Hjelp Av Forvirringsmatrise kan vi få nøyaktigheten av vår modell.
from sklearn.metrics import confusion_matrixcm = confusion_matrix(y_test, y_pred)du får en matrise cm .

Bruk cm til å beregne nøyaktighet som vist nedenfor:
Nøyaktighet = (cm + cm) /(Total test datapunkter)

her får vi nøyaktighet på 89 % . Skål!! vi får en god nøyaktighet.
Til Slutt Vil Vi Visualisere Vårt treningsresultat og Testresultat. Vi bruker matplotlib til å plotte datasettet vårt.
Visualisere Treningsresultatet
from matplotlib.colors import ListedColormapX_set, y_set = X_train, y_trainX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Training set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()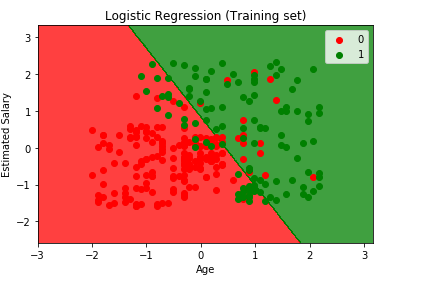
Visualisere Testresultatet
from matplotlib.colors import ListedColormapX_set, y_set = X_test, y_testX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Test set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()
nå kan du bygge din egen klassifikator for logistisk regresjon.
Takk!! Fortsett Å Kode !!
Merk: Dette er et gjestepost, og meningen i denne artikkelen er av gjesteforfatteren. Hvis du har noen problemer med noen av artiklene lagt ut på www.marktechpost.com please contact at [email protected]
Advertisement
