Ansiktsgjenkjenning-Trinn for Trinn
la oss takle dette problemet ett trinn om gangen. For hvert trinn lærer vi om en annen maskinlæringsalgoritme. Jeg skal ikke forklare hver eneste algoritme helt for å hindre at dette blir til en bok, men du lærer de viktigste ideene bak hver enkelt, og du lærer hvordan du kan bygge ditt eget ansiktsgjenkjenningssystem i Python ved Hjelp Av OpenFace og dlib.
Trinn 1: Finne Alle Ansikter
det første trinnet i vår rørledning er ansiktsgjenkjenning. Selvfølgelig må vi finne ansiktene i et fotografi før vi kan prøve å fortelle dem fra hverandre!
Hvis du har brukt et kamera i de siste 10 årene, har du sikkert sett ansiktsgjenkjenning i aksjon:

ansiktsgjenkjenning er en flott funksjon for kameraer. Når kameraet automatisk kan plukke ut ansikter, kan det sørge for at alle ansiktene er i fokus før det tar bildet. Men vi vil bruke den til et annet formål — å finne områdene av bildet vi ønsker å gi videre til neste trinn i vår pipeline.Ansiktsgjenkjenning ble vanlig på begynnelsen av 2000-tallet da Paul Viola og Michael Jones oppfant en måte å oppdage ansikter som var raske nok til å kjøre på billige kameraer. Men det finnes mye mer pålitelige løsninger nå. Vi skal bruke en metode oppfunnet i 2005 kalt Histogram Av Orienterte Gradienter-eller BARE HOG for kort.
for å finne ansikter i et bilde, begynner vi med å gjøre bildet vårt svart og hvitt fordi vi ikke trenger fargedata for å finne ansikter:

så ser vi på hver eneste piksel i bildet vårt en om gangen. For hver enkelt piksel vil vi se på pikslene som omgir den direkte:

vårt mål er å finne ut hvor mørkt den nåværende pikselen er i forhold til pikslene som omgir den. Da ønsker vi å tegne en pil som viser i hvilken retning bildet blir mørkere:

blir mørkere mot øvre høyre.
hvis du gjentar denne prosessen for hver eneste piksel i bildet, ender du opp med at hver piksel blir erstattet av en pil. Disse pilene kalles gradienter, og de viser strømmen fra lys til mørk over hele bildet:
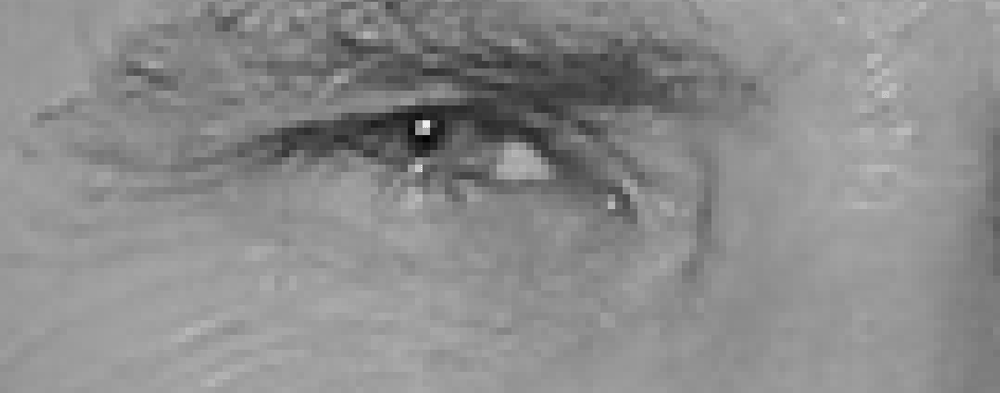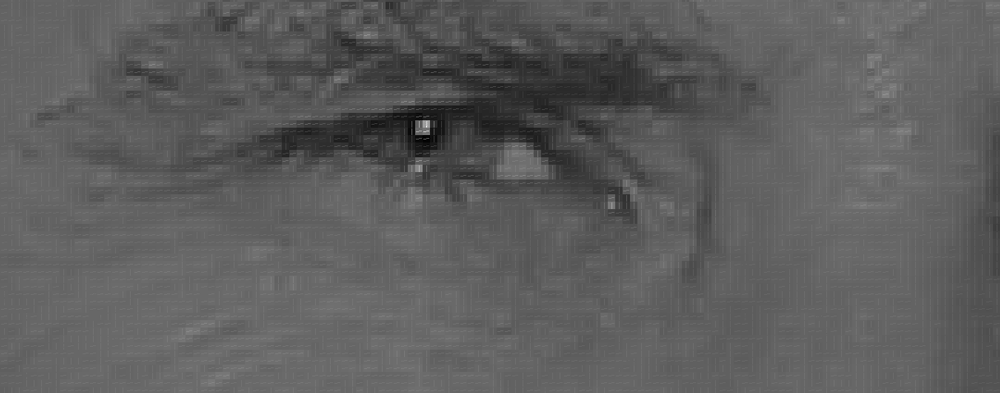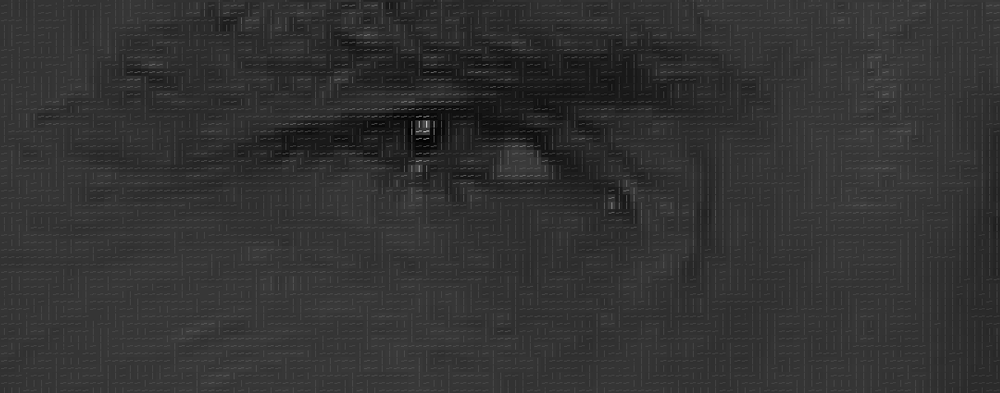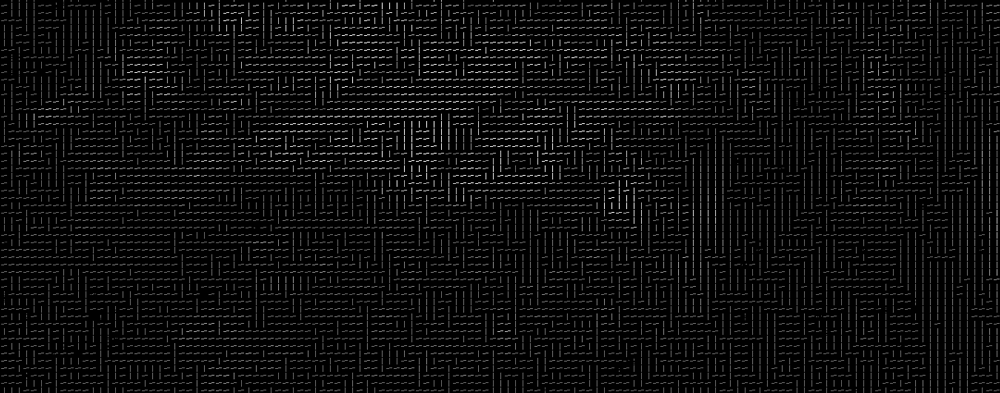
dette kan virke som en tilfeldig ting å gjøre, men det er en veldig god grunn til å erstatte pikslene med gradienter. Hvis vi analyserer piksler direkte, vil virkelig mørke bilder og virkelig lyse bilder av samme person ha helt forskjellige pikselverdier. Men ved å bare vurdere retningen som lysstyrken endres, vil både virkelig mørke bilder og virkelig lyse bilder ende opp med samme eksakte representasjon. Det gjør problemet mye enklere å løse!
men å lagre gradienten for hver enkelt piksel gir oss altfor mye detalj. Vi ender opp med å savne skogen for trærne. Det ville være bedre om vi bare kunne se den grunnleggende strømmen av lyshet / mørke på et høyere nivå, slik at vi kunne se bildets grunnleggende mønster.
For å gjøre dette, bryter vi opp bildet i små firkanter på 16×16 piksler hver. I hver rute teller vi opp hvor mange gradienter som peker i hver hovedretning(hvor mange peker opp, peker opp til høyre, peker til høyre osv.). Da vil vi erstatte den plassen i bildet med pilen retninger som var den sterkeste.
sluttresultatet er at vi gjør det opprinnelige bildet til en veldig enkel representasjon som fanger den grunnleggende strukturen til et ansikt på en enkel måte:

for å finne ansikter i DETTE HOGBILDET, er alt vi trenger å gjøre å finne den delen av bildet vårt som ser mest ut som et kjent HOGMØNSTER som ble hentet fra en rekke andre treningsflater:

:

hvis du vil prøve dette trinnet selv ved hjelp av python og dlib, er det kode som viser hvordan du genererer og viser hog-representasjoner av bilder.
Trinn 2: Poserer Og Projiserer Ansikter
Whew, vi isolerte ansiktene i bildet vårt. Men nå må vi håndtere problemet som ansikter slått forskjellige retninger ser helt annerledes til en datamaskin:

at begge bildene er av will ferrell, men datamaskiner ville se disse bildene som to helt forskjellige personer.
For å ta hensyn til dette, vil vi prøve å vri hvert bilde slik at øynene og leppene alltid er i prøveplassen i bildet. Dette vil gjøre det mye enklere for oss å sammenligne ansikter i de neste trinnene.
for å gjøre dette, skal vi bruke en algoritme kalt face landmark estimation. Det er mange måter å gjøre dette på, men vi skal bruke tilnærmingen oppfunnet i 2014 av Vahid Kazemi og Josephine Sullivan.den grunnleggende ideen er at vi vil komme opp med 68 spesifikke punkter (kalt landemerker) som finnes på hvert ansikt — toppen av haken, utsiden av hvert øye, den indre kanten av hvert øyenbryn, etc. Da skal vi trene en maskinlæringsalgoritme for å kunne finne disse 68 spesifikke punktene på et ansikt:

her er resultatet av å finne de 68 ansiktsmarkene på testbildet vårt:

Nå som vi vet hvor øynene og munnen er, vil vi bare rotere, skalere og skjære bildet slik at øynene og munnen er sentrert så godt som mulig. Vi vil ikke gjøre noen fancy 3d warps fordi det ville introdusere forvrengninger i bildet. Vi skal bare bruke grunnleggende bildetransformasjoner som rotasjon og skala som bevarer parallelle linjer (kalt affine transformasjoner):

nå, uansett hvordan ansiktet er vendt, kan vi sentrere øynene og munnen i omtrent samme posisjon i bildet. Dette vil gjøre vårt neste skritt mye mer nøyaktig.
hvis du vil prøve dette trinnet selv ved Hjelp Av Python og dlib, er det koden for å finne ansiktsmarkeder, og her er koden for å transformere bildet ved hjelp av disse landemerkene.
Trinn 3: Koding Ansikter
Nå er vi til kjøtt av problemet – faktisk fortelle ansikter fra hverandre. Det er her ting blir veldig interessant!Den enkleste tilnærmingen til ansiktsgjenkjenning er å sammenligne det ukjente ansiktet vi fant I Trinn 2 med alle bildene vi har av folk som allerede er merket. Når vi finner et tidligere merket ansikt som ser veldig ut som vårt ukjente ansikt, må det være samme person. Virker som en ganske god ide, ikke sant?
det er faktisk et stort problem med den tilnærmingen. Et nettsted Som Facebook med milliarder av brukere og en billion bilder kan ikke muligens sløyfe gjennom hvert tidligere merket ansikt for å sammenligne det med hvert nylig opplastede bilde. Det ville ta altfor lang tid. De må kunne gjenkjenne ansikter i millisekunder, ikke timer.
Det vi trenger er en måte å trekke ut noen grunnleggende målinger fra hvert ansikt. Da kunne vi måle vårt ukjente ansikt på samme måte og finne det kjente ansiktet med de nærmeste målingene. For eksempel kan vi måle størrelsen på hvert øre, avstanden mellom øynene, lengden på nesen, etc. Hvis DU noen gang har sett et dårlig forbrytelsesshow som CSI, vet du hva JEG snakker om:
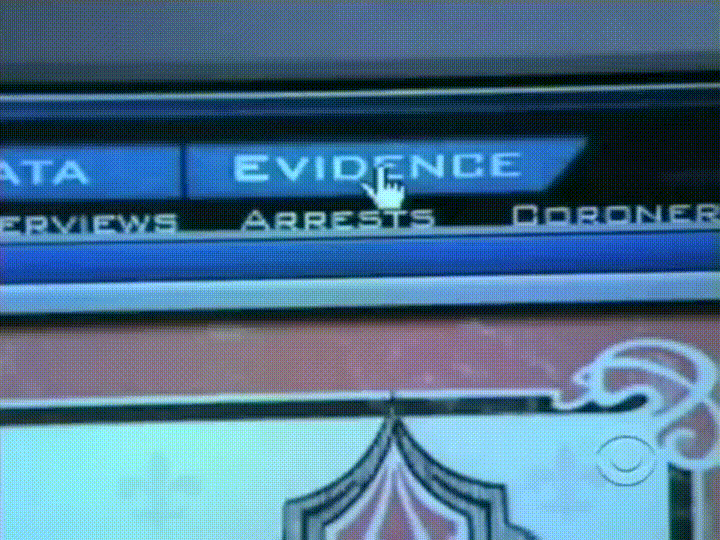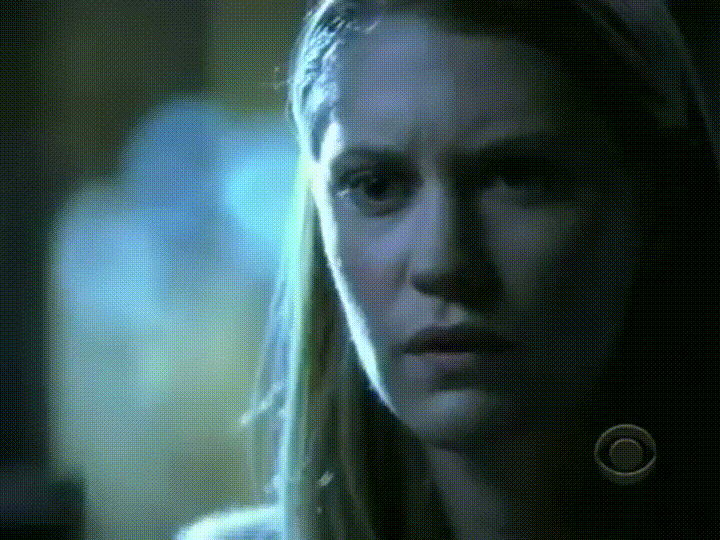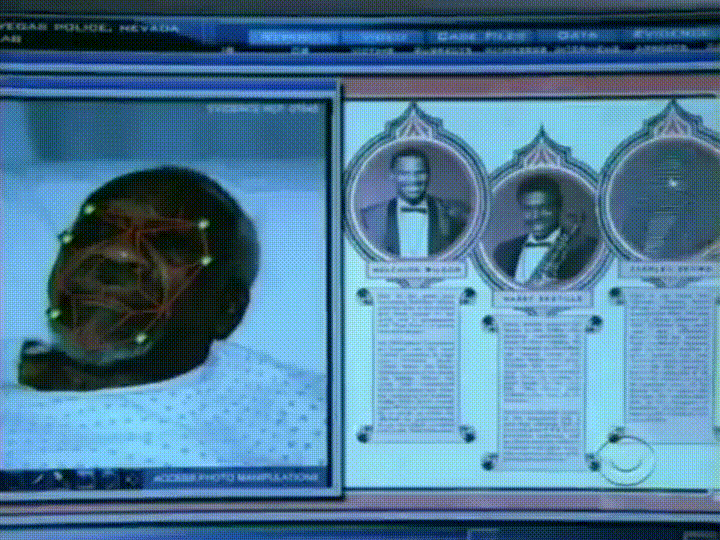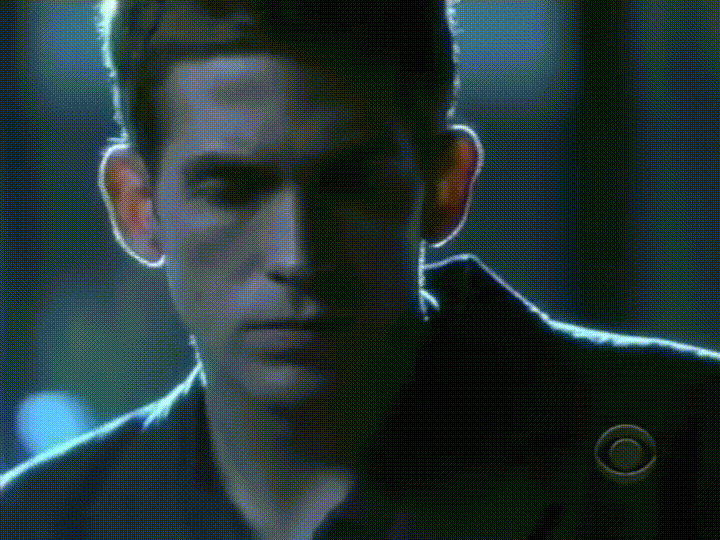
Den mest pålitelige måten å måle et ansikt på
Ok, så hvilke målinger skal vi samle inn fra hvert ansikt for å bygge vår kjente ansiktsdatabase? Ørestørrelse? Nese lengde? Øyenfarge? Noe annet?det viser seg at målingene som virker åpenbare for oss mennesker (som øyenfarge) ikke gir mening for en datamaskin som ser på individuelle piksler i et bilde. Forskere har oppdaget at den mest nøyaktige tilnærmingen er å la datamaskinen finne ut målingene for å samle seg selv. Dyp læring gjør en bedre jobb enn mennesker på å finne ut hvilke deler av et ansikt er viktig å måle.løsningen er å trene Et Dypt Innviklet Nevralt Nettverk (akkurat som Vi gjorde I Del 3). Men i stedet for å trene nettverket for å gjenkjenne bildeobjekter som vi gjorde sist, skal vi trene den for å generere 128 målinger for hvert ansikt.
treningsprosessen fungerer ved å se på 3 ansiktsbilder om gangen:
- Last inn et treningsansiktsbilde av en kjent person
- Last inn et annet bilde av den samme kjente personen
- Last inn et bilde av en helt annen person
så ser algoritmen på målingene den for øyeblikket genererer for hver av de tre bildene. Det tweaks deretter nevrale nettverket litt slik at det sørger for at målingene det genererer for #1 og #2 er litt nærmere, samtidig som målingene for #2 og #3 er litt lenger fra hverandre:

etter å ha gjentatt dette trinnet millioner av ganger for millioner av bilder av tusenvis av forskjellige mennesker, lærer det nevrale nettverket pålitelig å generere 128 målinger for hver person. Noen ti forskjellige bilder av samme person bør gi omtrent samme målinger.
Maskinlæring folk kaller 128 målinger av hvert ansikt en innebygging. Ideen om å redusere kompliserte rådata som et bilde i en liste over datagenererte tall kommer opp mye i maskinlæring (spesielt i språkoversettelse). Den nøyaktige tilnærmingen til ansikter vi bruker ble oppfunnet i 2015 av forskere Ved Google, men mange lignende tilnærminger eksisterer.
Koding av vårt ansiktsbilde
denne prosessen med å trene et innviklet nevralt nettverk for å utføre ansiktsinnbygginger krever mye data og datakraft. Selv med et dyrt NVidia Telsa-skjermkort, tar det omtrent 24 timer med kontinuerlig trening for å få god nøyaktighet.Men når nettverket har blitt trent, kan det generere målinger for ethvert ansikt, selv de det aldri har sett før! Så dette trinnet må bare gjøres en gang. Heldig for oss, de fine folkene På OpenFace gjorde allerede dette, og de publiserte flere trente nettverk som vi direkte kan bruke. Takk Brandon Amos og teamet!Så alt vi trenger å gjøre selv er å kjøre våre ansiktsbilder gjennom deres pre-trente nettverk for å få 128 målinger for hvert ansikt. Her er målingene for testbildet vårt:

så hvilke deler av ansiktet måler disse 128 tallene nøyaktig? Det viser seg at vi ikke har noen anelse. Det spiller ingen rolle for oss. Alt vi bryr oss om er at nettverket genererer nesten de samme tallene når man ser på to forskjellige bilder av samme person.
Hvis Du vil prøve dette trinnet selv, Gir OpenFace et lua-skript som vil generere embeddings alle bilder i en mappe og skrive dem til en csv-fil. Du kjører det slik.
Trinn 4: Å Finne personens navn fra kodingen
Dette siste trinnet er faktisk det enkleste trinnet i hele prosessen. Alt vi trenger å gjøre er å finne personen i vår database med kjente personer som har de nærmeste målingene til vårt testbilde.
du kan gjøre det ved å bruke en hvilken som helst grunnleggende klassifiseringsalgoritme for maskinlæring. Ingen fancy dyp læring triks er nødvendig. Vi bruker en enkel lineær SVM klassifikator, men mange klassifiseringsalgoritmer kan fungere.
Alt vi trenger å gjøre er å trene en klassifikator som kan ta inn målingene fra et nytt testbilde og forteller hvilken kjent person som er nærmeste kamp. Kjører denne klassifikatoren tar millisekunder. Resultatet av klassifikatoren er navnet på personen!
Så la oss prøve ut vårt system. Først trente jeg en klassifikator med innbyggingene på ca 20 bilder Hver Av Will Ferrell, Chad Smith og Jimmy Falon: