
«det finnes tre typer løgner – løgner, jævla løgner.løgn Og Statistikk.»- Benjamin Disraeli
Statistiske analyser har historisk vært en stalwart av høyteknologiske og avanserte forretningsindustrier, og i dag er de viktigere enn noensinne. Med fremveksten av avansert teknologi og globaliserte operasjoner, gir statistiske analyser bedrifter et innblikk i å løse de ekstreme usikkerhetene i markedet. Studier fremmer informert beslutningstaking, gode vurderinger og handlinger utført på vekten av bevis, ikke forutsetninger.
som bedrifter er ofte tvunget til å følge en vanskelig å tolke markedet veikart, statistiske metoder kan hjelpe med planlegging som er nødvendig for å navigere et landskap fylt med jettegryter, fallgruver og fiendtlig konkurranse. Statistiske studier kan også bistå i markedsføring av varer eller tjenester, og i å forstå hver målmarkeder unike verdidrivere. I den digitale tidsalderen blir disse evnene bare ytterligere forbedret og utnyttet gjennom implementering av avansert teknologi og business intelligence-programvare. Hvis alt dette er sant, hva er problemet med statistikk?
egentlig er det ikke noe problem i seg selv-men det kan være. Statistikk er beryktet for sin evne og potensial til å eksistere som villedende og dårlige data.
Hva Er En Misvisende Statistikk?
Villedende statistikk er rett og slett misusage-målrettet eller ikke – av en numerisk data. Resultatene gir en misvisende informasjon til mottakeren, som da mener noe galt hvis han eller hun ikke merker feilen eller ikke har full data bilde.
Gitt betydningen av data i dagens raskt utviklende digitale verden, er det viktig å være kjent med grunnleggende om villedende statistikk og tilsyn. Som en øvelse i due diligence vil vi gjennomgå noen av de vanligste formene for misbruk av statistikk, og ulike alarmerende (og dessverre vanlige) villedende statistikkeksempler fra det offentlige liv.
Er Statistikk Pålitelig?
73,6% av statistikken er falsk. Virkelig? Nei, selvfølgelig er det et sammensatt nummer (selv om en slik studie ville være interessant å vite – men igjen, kunne ha alle feilene det prøver på samme tid å påpeke). Statistisk pålitelighet er avgjørende for å sikre nøyaktigheten og gyldigheten av analysen. For å sikre at påliteligheten er høy, er det ulike teknikker å utføre-først av dem er kontrolltester, som skal ha lignende resultater når du reproduserer et eksperiment under lignende forhold. Disse kontrollerende tiltakene er avgjørende og bør være en del av ethvert eksperiment eller undersøkelse – dessverre er det ikke alltid tilfelle.
mens tall ikke lyver, kan de faktisk brukes til å villede med halvsannheter. Dette er kjent som «misbruk av statistikk.»Det antas ofte at misbruk av statistikk er begrenset til de individer eller selskaper som ønsker å få fortjeneste ved å forvride sannheten, det være seg økonomi, utdanning eller massemedier.
fortellingen av halvsannheter gjennom studier er imidlertid ikke bare begrenset til matematiske amatører. En undersøkende undersøkelse Fra 2009 av Dr. Daniele Fanelli fra University Of Edinburgh fant at 33,7% av de undersøkte forskerne innrømmet tvilsom forskningspraksis, inkludert endring av resultater for å forbedre resultatene, subjektiv datatolkning, tilbakeholdelse av analytiske detaljer og slippe observasjoner på grunn av tarmfølelser. Forskere!
mens tall ikke alltid må være fabrikkert eller misvisende, er det klart at selv samfunn mest pålitelige numeriske portvakter ikke er immun mot uforsiktighet og skjevhet som kan oppstå med statistiske tolkningsprosesser. Det er forskjellige måter hvordan statistikk kan være misvisende at vi vil detalj senere. Den vanligste er selvfølgelig korrelasjon versus årsakssammenheng, som alltid utelater en annen (eller to eller tre) faktor som er den faktiske årsaken til problemet. Drikke te øker diabetes med 50%, og skallethet øker kardiovaskulær sykdomsrisiko opptil 70%! Glemte vi å nevne mengden sukker i teen, eller det faktum at skallethet og alderdom er relatert – akkurat som kardiovaskulær sykdomsrisiko og alderdom?
så kan statistikk manipuleres? Det kan de. Lyver tallene? Du kan være dommer.
Hvordan Statistikk kan Være Misvisende

Husk at misbruk av statistikk kan være tilfeldig eller målrettet. Mens en ondsinnet hensikt å sløre linjer med villedende statistikk sikkert vil forstørre bias, er hensikt ikke nødvendig for å skape misforståelser. Misbruk av statistikk er et mye bredere problem som nå gjennomsyrer flere bransjer og fagområder. Her er noen potensielle uhell som ofte fører til misbruk:
- feil polling
måten spørsmål blir formulert på, kan ha stor innvirkning på måten et publikum svarer på dem. Spesifikke ordlyd mønstre har en overbevisende effekt og indusere respondentene til å svare på en forutsigbar måte. For eksempel, på en meningsmåling som søker skattemessige meninger, la oss se på de to potensielle spørsmålene:
– tror du at du skal beskattes slik at andre borgere ikke trenger å jobbe?- Tror du at regjeringen skal hjelpe dem som ikke kan finne arbeid?
disse to spørsmålene vil sannsynligvis provosere langt forskjellige svar, selv om de håndterer samme tema for statsstøtte. Dette er eksempler på » lastet spørsmål.»
en mer nøyaktig måte å formulere spørsmålet ville være, » Støtter du regjeringens hjelpeprogrammer for arbeidsledighet?»eller, (enda mer nøytralt)» Hva er ditt syn på arbeidsledighetsstøtte?»
de to sistnevnte eksemplene på de opprinnelige spørsmålene eliminerer enhver slutning eller forslag fra polleren, og er dermed betydelig mer upartisk. En annen urettferdig metode for avstemning er å stille et spørsmål, men før det med en betinget uttalelse eller en faktumerklæring. Bor med vårt eksempel, ville det se slik ut: «Gitt de stigende kostnadene til middelklassen, støtter du statsstøtteprogrammer?»
en god tommelfingerregel er å alltid ta avstemning med en klype salt, og for å prøve å gjennomgå spørsmålene som faktisk ble presentert. De gir god innsikt, ofte mer enn svarene.
- Feil korrelasjoner
problemet med korrelasjoner er dette: hvis du måler nok variabler, vil det til slutt se ut som noen av dem korrelerer. Som en av tjue vil uunngåelig bli ansett som signifikant uten direkte korrelasjon, kan studier manipuleres (med nok data) for å bevise en korrelasjon som ikke eksisterer eller som ikke er signifikant nok til å bevise årsakssammenheng.
for å illustrere dette punktet videre, la oss anta at en studie har funnet en sammenheng mellom en økning i bilulykker I Delstaten New York i juni måned (a), og en økning i bjørnangrep I delstaten New York i juni måned (b).
det betyr at det sannsynligvis vil være seks mulige forklaringer:
– bilulykker (a) forårsaker bjørnangrep (B)- Bjørnangrep (B) forårsaker bilulykker (a) Og bjørnangrep (b) delvis forårsaker hverandre – Bilulykker (A) Og bjørnangrep (B) skyldes en tredje faktor (C) – Bjørnangrep (B)) er forårsaket Av en tredje faktor (c) som korrelerer til bilulykker (a) – korrelasjonen Er bare sjanse
enhver fornuftig person ville lett identifisere det faktum at bilulykker ikke forårsaker Bjørnangrep. Hver er sannsynligvis et resultat av en tredje faktor, som blir: en økt befolkning, på grunn av høy turisme sesongen i juni måned. Det ville være absurd å si at de forårsaker hverandre… og det er nettopp derfor det er vårt eksempel. Det er lett å se en sammenheng.
men hva med årsakssammenheng? Hva om de målte variablene var forskjellige? Hva om Det var noe mer troverdig, Som Alzheimers og alderdom? Det er klart at det er en sammenheng mellom de to, men er det årsakssammenheng? Mange ville feilaktig anta, ja, utelukkende basert på styrken av korrelasjonen. Trå varsomt, for enten bevisst eller uvitende, korrelasjon jakt vil fortsette å eksistere innenfor statistiske studier.
- datafiske
dette misvisende dataeksemplet er også referert til som «datamudring» (og relatert til feil korrelasjoner). Det er en data mining teknikk der ekstremt store mengder data analyseres for å oppdage relasjoner mellom datapunkter. Søker et forhold mellom data er ikke en data misbruk per se, derimot, gjør det uten en hypotese er.
datamudring Er en selvbetjent teknikk som ofte brukes for det uetiske formål å omgå tradisjonelle data mining teknikker, for å søke ytterligere data konklusjoner som ikke eksisterer. Dette er ikke å si at det ikke er riktig bruk av datautvinning, da det faktisk kan føre til overraskende avvik og interessante analyser. Derimot, oftere enn ikke, data mudring brukes til å anta eksistensen av data relasjoner uten videre studier.
ofte resulterer datafiske i studier som er svært publiserte på grunn av deres viktige eller outlandish funn. Disse studiene er veldig snart motsagt av andre viktige eller outlandish funn. Disse falske korrelasjoner ofte la allmennheten veldig forvirret, og søker etter svar om betydningen av årsakssammenheng og korrelasjon.
På Samme måte er en annen vanlig praksis med data utelatelsen, noe som betyr at etter å ha sett på et stort datasett av svar, velger du bare de som støtter dine synspunkter og funn og utelater de som motsier det. Som nevnt i begynnelsen av denne artikkelen har det vist seg at en tredjedel av forskerne innrømmet at de hadde tvilsom forskningspraksis, inkludert å holde tilbake analytiske detaljer og endre resultater…! Men igjen står vi overfor en studie som selv kan falle inn i disse 33% av tvilsom praksis, feil valg, selektiv bias… Det blir vanskelig å tro noen analyse!
- Misvisende datavisualisering
Innsiktsfulle grafer og diagrammer inkluderer veldig grunnleggende, men viktig, gruppering av elementer. Uansett hvilke typer datavisualisering du velger å bruke, må den formidle:
– skalaene som brukes – startverdien (null eller på annen måte)- beregningsmetoden (f. eks. datasett og tidsperiode)
Uten disse elementene, bør visuelle datarepresentasjoner ses med et saltkorn, med tanke på de vanlige datavisualiseringsfeilene man kan gjøre. Mellomliggende datapunkter bør også identifiseres og kontekst gis dersom det vil tilføre verdi til informasjonen som presenteres. Med den økende avhengigheten av intelligent løsningsautomatisering for variable datapunkt sammenligninger, bør beste praksis (dvs. design og skalering) implementeres før du sammenligner data fra forskjellige kilder, datasett, tider og steder.
- Målrettet og selektiv bias
det siste av våre vanligste eksempler på misbruk av statistikk og villedende data er kanskje det mest alvorlige. Målrettet skjevhet er bevisst forsøk på å påvirke data funn uten selv feigning faglig ansvarlighet. Bias er mest sannsynlig å ta form av data utelatelser eller justeringer.
den selektive bias er litt mer diskret for hvem leser ikke de små linjene. Det faller vanligvis ned på prøven av undersøkte personer. For eksempel, arten av gruppen av personer som ble undersøkt: spør en klasse av høyskole student om den juridiske drikkealderen, eller en gruppe pensjonister om eldreomsorgssystemet. Du vil ende opp med en statistisk feil kalt «selektiv bias».
- ved hjelp av prosentvis endring i kombinasjon med en liten prøvestørrelse
en annen måte å lage villedende statistikk, også knyttet til valg av prøve diskutert ovenfor, er størrelsen på prøven. Når et eksperiment eller en undersøkelse ledes på en helt ikke signifikant utvalgsstørrelse, vil ikke bare resultatene være ubrukelige, men måten å presentere dem-nemlig som prosenter – vil være helt misvisende.
Stiller et spørsmål til en utvalgsstørrelse på 20 personer, hvor 19 svarer «ja»(=95% sier ja) versus å stille det samme spørsmålet til 1000 personer og 950 svarer » ja » (=95% også): gyldigheten av prosentandelen er tydeligvis ikke den samme. Å gi utelukkende prosentandelen av endring uten de totale tallene eller utvalgsstørrelsen vil være helt misvisende. xkdcs tegneserie illustrerer dette veldig bra, for å vise hvordan det» raskest voksende » kravet er en helt relativ markedsføringstale:

På Samme måte er den nødvendige prøvestørrelsen påvirket av hva slags spørsmål du spør, den statistiske signifikansen du trenger (klinisk studie vs business studie), og statistisk teknikk. Hvis du utfører en kvantitativ analyse, er utvalgsstørrelser under 200 personer vanligvis ugyldige.
Misvisende Statistikk Eksempler i Det Virkelige Liv
nå som vi har gjennomgått flere av de mest commons metoder for data misbruk, la oss se på ulike digitale tidsalder eksempler på misvisende statistikk over tre distinkte, men relatert, spektrum: media og politikk, reklame og vitenskap. Mens visse emner som er oppført her, sannsynligvis vil røre følelser avhengig av ens synspunkt, er deres inkludering bare for datademonstrasjonsformål.
- eksempler på villedende statistikk i media og politikk
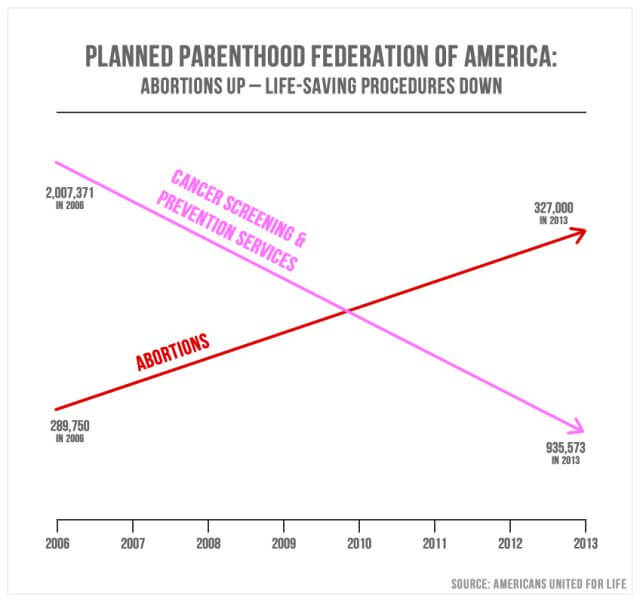
villedende statistikk i media er ganske vanlig. På September. 29, 2015, Republikanere fra Den AMERIKANSKE Kongressen spurte Cecile Richards, presidenten For Planned Parenthood, om misbruk av $500 millioner i årlig føderal finansiering. Ovennevnte graf / diagram ble presentert som et vektpunkt.
Representant Jason Chaffetz Fra Utah forklarte: «i rosa, det er reduksjonen i brysteksamenene, og den røde er økningen i abortene. Det er det som skjer i din organisasjon.»
basert på strukturen i diagrammet, ser det faktisk ut til å vise at antall aborter siden 2006 opplevde betydelig vekst, mens antall kreftundersøkelser ble betydelig redusert. Hensikten er å formidle et skifte i fokus fra kreftundersøkelser til abort. Kartpunktene ser ut til å indikere at 327 000 aborter er større i iboende verdi enn 935 573 kreftundersøkelser. Likevel vil nærmere undersøkelse avsløre at diagrammet ikke har noen definert y-akse. Dette betyr at det ikke er noen definerbar begrunnelse for plasseringen av de synlige målelinjene.
Politifact, et faktasjekkingsnettsted for advokatvirksomhet, gjennomgikk Rep. Chaffetzs tall via en sammenligning med Planned Parenthood egne årsrapporter. Ved hjelp av en klart definert skala, her er hva informasjonen ser ut:

og som dette med en annen gyldig skala:
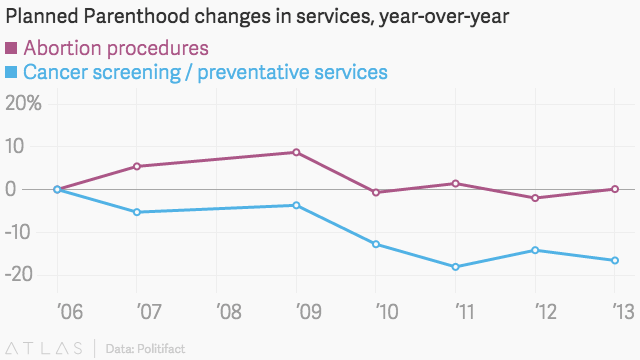
når det er plassert innenfor en klart definert skala, blir det tydelig at mens antall kreftundersøkelser faktisk har gått ned, er det fortsatt langt høyere enn antall abortprosedyrer som utføres årlig. Som sådan er dette et godt misvisende statistikkeksempel, og noen kan argumentere for bias med tanke på at diagrammet ikke stammer fra Kongressmannen, men Fra Amerikanerne United For Life, en anti-abortgruppe. Dette er bare ett av mange eksempler på villedende statistikk i media og politikk.
- Villedende statistikk i reklame

I 2007 Ble Colgate bestilt av advertising standards authority (asa) i storbritannia for å forlate sin påstand: «mer enn 80% av tannleger anbefaler colgate.»Slagordet i spørsmålet ble plassert på en reklameplakat i STORBRITANNIA, og ble ansett for å være i strid MED BRITISKE annonseringsregler.
påstanden, som var basert på undersøkelser av tannleger og hygienister utført av produsenten, ble funnet å være uriktig representativ da det tillot deltakerne å velge ett eller flere tannkrem merker. ASA uttalte at påstanden » … ville bli forstått av leserne til å bety at 80 prosent av tannleger anbefaler Colgate utover andre merker, og de resterende 20 prosent vil anbefale forskjellige merker.»
ASA fortsatte, » Fordi vi forsto at en annen konkurrents merkevare ble anbefalt nesten like mye Som Colgate-merket av tannlegerne som ble undersøkt, konkluderte vi med at påstanden misvisende antydet at 80 prosent av tannleger anbefaler Colgate tannkrem fremfor alle andre merker.»ASA hevdet også at skriptene som ble brukt til undersøkelsen informerte deltakerne om at forskningen ble utført av et uavhengig forskningsselskap, som iboende var falsk.
basert på misbruk teknikker vi dekket, er det trygt å si at Denne sleight off-hand teknikk Av Colgate er klart eksempel på villedende statistikk i reklame, og vil falle under feil valg og direkte skjevhet.
- Villedende statistikk i vitenskapen
i likhet med abort er global oppvarming et annet politisk ladet tema som sannsynligvis vil vekke følelser. Det skjer også å være et tema som er kraftig godkjent av både motstandere og talsmenn via studier. La oss ta en titt på noen av bevisene for og imot.
det er generelt enighet om at den globale gjennomsnittstemperaturen i 1998 var 58,3 grader Fahrenheit. DETTE er IFØLGE NASAS GODDARD Institute For Space Studies. I 2012 ble den globale gjennomsnittstemperaturen målt til 58,2 grader. Det er derfor hevdet av global oppvarming motstandere at, da det var en 0.1 grad nedgang i den globale gjennomsnittstemperaturen over en 14-års periode, er global oppvarming motbevist.
grafen nedenfor er den som oftest refereres til for å motbevise den globale oppvarmingen. Det demonstrerer endringen i lufttemperatur (Celsius) fra 1998 til 2012.
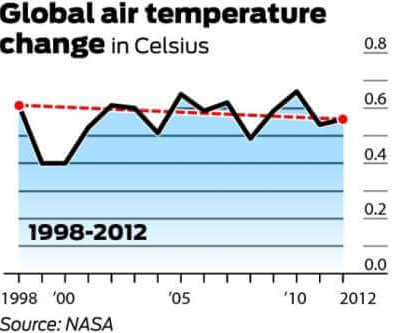
det er verdt å nevne at 1998 var en av de varmeste årene på rekord på grunn Av en unormalt sterk el Niñ vindstrøm. Det er også verdt å merke seg at, da det er stor grad av variabilitet i klimasystemet, måles temperaturer vanligvis med minst en 30-års syklus. Diagrammet nedenfor uttrykker den 30-årige endringen i globale gjennomsnittstemperaturer.
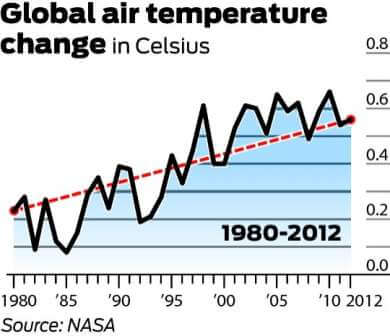
og se nå på trenden fra 1900 til 2012: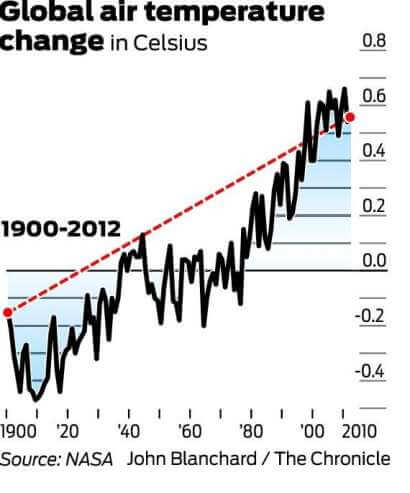
mens de langsiktige dataene kan synes å reflektere et platå, maler det tydelig et bilde av gradvis oppvarming. Derfor, ved å bruke den første grafen, og bare den første grafen, for å motbevise global oppvarming, er et perfekt misvisende statistikkeksempel.
Slik Leser Du Statistikk med Avstand
en første god ting ville selvfølgelig være å stå foran en ærlig undersøkelse/eksperiment / forskning – velg den du har under øynene dine-som har brukt de riktige teknikkene for innsamling og tolkning av data. Men du kan ikke vite før du spør deg selv et par spørsmål og analysere resultatene du har i mellom hendene.
som entreprenør Og tidligere konsulent Mark Suster anbefaler I en artikkel, bør du lure på hvem som gjorde den primære undersøkelsen av analysen. Uavhengig universitet studiegruppe, lab-tilknyttet forskerteam, konsulentselskap? Derfra stammer naturlig ut spørsmålet: hvem betalte dem? Siden ingen jobber gratis, er det alltid interessant å vite hvem som sponser forskningen. På samme måte, hva er motivene bak forskningen? Hva prøvde forskeren eller statistikerne å finne ut? Til slutt, hvor stor var prøven satt og hvem var en del av det? Hvor inkluderende var det?
dette er viktige spørsmål å tenke på og svare på før de sprer seg overalt skjeve eller partiske resultater – selv om det skjer hele tiden, på grunn av forsterkning. Et typisk eksempel på forsterkning skjer ofte med aviser og journalister, som tar ett stykke data og trenger å gjøre det til overskrifter – dermed ofte ut av sin opprinnelige sammenheng. Ingen kjøper et magasin der det står at neste år vil det samme skje I XYZ-markedet som i år – selv om det er sant. Redaktører, klienter og folk vil ha noe nytt, ikke noe de vet; derfor ender vi ofte med et forsterkningsfenomen som blir ekko og mer enn det burde.
Misbruk Av Statistikk-Et Sammendrag
til spørsmålet » kan statistikk manipuleres?», kan vi ta opp 6 metoder som ofte brukes-med vilje eller ikke – som skiller analysen og resultatene. Her er vanlige typer misbruk av statistikk:
- feil valg
- feil korrelasjoner
- data fiske
- Misvisende datavisualisering
- Målrettet og selektiv bias
- ved hjelp av prosentvis endring i kombinasjon med en liten utvalgsstørrelse
nå som du kjenner dem, blir det lettere å få øye på dem og stille spørsmål til all statistikk som er gitt til deg hver dag. På samme måte, for å sikre at du holder en viss avstand til studiene og undersøkelsene du leser, husk spørsmålene du skal stille deg selv-hvem forsket og hvorfor, hvem betalte for det, hva var prøven.
Åpenhet og Datadrevne Forretningsløsninger
selv om det er helt klart at statistiske data har potensial til å bli misbrukt, kan det også etisk drive markedsverdi i den digitale verden. Big data har evnen til å gi digitale tidsalder bedrifter med et veikart for effektivitet og åpenhet, og til slutt, lønnsomhet. Avanserte teknologiløsninger som online rapportering programvare kan forbedre statistiske datamodeller, og gi digitale tidsalder bedrifter med en step-up på konkurrentene.
enten det gjelder markedsintelligens, kundeopplevelse eller forretningsrapportering, er fremtiden for data nå. Ta vare på å bruke data ansvarlig, etisk og visuelt, og se din gjennomsiktige bedriftsidentitet vokse.