Hva Er Regulært Uttrykk I Python?
Et Regulært Uttrykk (RE) i et programmeringsspråk er en spesiell tekststreng som brukes til å beskrive et søkemønster. Det er svært nyttig for å trekke ut informasjon fra tekst som kode, filer, logg, regneark eller dokumenter.
Mens Du bruker Python regulære uttrykk det første er å gjenkjenne er at alt er egentlig et tegn, og vi skriver mønstre for å matche en bestemt sekvens av tegn også referert til som streng. Ascii eller latinske bokstaver er de som er på tastaturer Og Unicode brukes til å matche utenlandsk tekst. Det inkluderer sifre og tegnsetting og alle spesialtegn som$#@!%, osv.
I Denne Python RegEx opplæringen, vil vi lære –
- Regulært Uttrykk Syntaks
- Eksempel på w+ Og ^ Uttrykk
- Eksempel på \s uttrykk i re.split funksjon
- ved hjelp av regulære uttrykksmetoder
- Ved hjelp av re.match ()
- Finne Mønster I Tekst (re .søk ())
- Ved hjelp av re.findall for tekst
- Python Flagg
- Eksempel på re.For eksempel kan Et Python regulært uttrykk fortelle et program å søke etter bestemt tekst fra strengen og deretter skrive ut resultatet tilsvarende. Uttrykk kan inkludere
- tekst matchende
- Repetisjon
- Forgrening
- Mønster-komposisjon etc.Regulært uttrykk Eller RegEx i Python er betegnet SOM RE (REs, regexes eller regex mønster) importeres gjennom re modul. Python støtter regulære uttrykk gjennom biblioteker. RegEx i Python støtter ulike ting som Modifikatorer, Identifikatorer og Hvite mellomrom.
Identifikatorer Modifikatorer mellomrom tegn Escape kreves \d= et hvilket som helst tall (et siffer) \d representerer et siffer.Ex: \d{1,5} det vil erklære siffer mellom 1,5 som 424,444,545 etc. \n = ny linje . + * ? $ ^ () {} | \ \d= alt annet enn et tall (et ikke-siffer) + = matcher 1 eller mer \s= mellomrom (fane,mellomrom,linjeskift osv.) ? = matches 0 or 1 \t =tab \S= anything but a space * = 0 or more \e = escape \w = letters ( Match alphanumeric character, including «_») $ match end of a string \r = carriage return \W =anything but letters ( Matches a non-alphanumeric character excluding «_») ^ match start of a string \f= form feed . = anything but letters (periods) | matches either or x/y —————– \b = any character except for new line = range or «variance» —————- \. {x} = denne mengden av foregående kode —————– Regular Expression(RE) Syntaks
import re
- «re» modul som følger med Python primært brukt for streng søking og manipulasjon
- også brukt ofte for web-side «Skraping» (trekke ut store mengder vi vil begynne uttrykksopplæringen med denne enkle øvelsen ved å bruke uttrykkene (w+) og (^).
Eksempel på w+ Og ^ Uttrykk
- «^»: Dette uttrykket samsvarer med starten på en streng
- «w+»: dette uttrykket samsvarer med det alfanumeriske tegnet i strengen
Her ser Vi Et Python RegEx-Eksempel på hvordan vi kan bruke w + og ^ uttrykk i koden vår. Vi dekker funksjonen re.findall () I Python, senere i denne opplæringen, men for en stund fokuserer vi bare på \w + og \ ^ uttrykk.
For eksempel, for vår streng «guru99, utdanning er gøy» hvis vi utfører koden med w + og^, vil den gi utgangen «guru99».
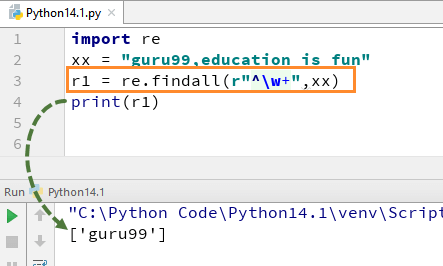
import rexx = "guru99,education is fun"r1 = re.findall(r"^\w+",xx)print(r1)
Husk At hvis du fjerner +tegn fra w+, vil utgangen endres, og det vil bare gi det første tegnet i første bokstav, dvs.
Eksempel på \ s uttrykk i re.split funksjon
- «s»: dette uttrykket brukes til å lage et mellomrom i strengen
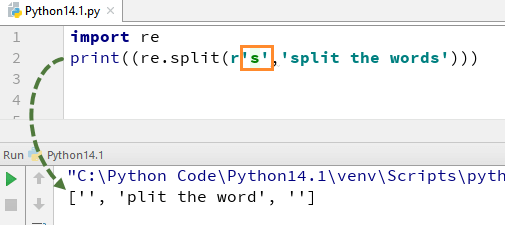
for å forstå hvordan Denne Regexen i Python fungerer, begynner vi Med et Enkelt Python RegEx Eksempel på en delt funksjon. I eksemplet har vi delt hvert ord ved hjelp av » re.split » funksjon og samtidig har vi brukt uttrykk \s som gjør det mulig å analysere hvert ord i strengen separat.

Når du utfører denne koden, vil den gi deg utgangen .
nå, la oss se hva som skjer hvis du fjerner «\» fra s. det er ikke noe ‘s’ alfabet i utgangen, dette er fordi vi har fjernet ‘ \ ‘ fra strengen, og det evaluerer «s» som et vanlig tegn og dermed deler ordene hvor det finner «s» i strengen.
På Samme måte er det serier av Andre Python regulære uttrykk som du kan bruke på ulike måter I Python som \d, \ D,$,\., \b, etc.
her er den komplette koden
import rexx = "guru99,education is fun"r1 = re.findall(r"^\w+", xx)print((re.split(r'\s','we are splitting the words')))print((re.split(r's','split the words')))
Neste skal vi se hvilke typer metoder som brukes med vanlig uttrykk i Python.
ved hjelp av regulære uttrykksmetoder
«re» – pakken inneholder flere metoder for å faktisk utføre spørringer på en inngangsstreng. Vi vil se metodene for re I Python:
- re.match ()
- re.søk()
- re.findall ()
Merk: Basert på regulære uttrykk, Tilbyr Python to forskjellige primitive operasjoner. Match-metoden sjekker bare for en kamp i begynnelsen av strengen mens søk sjekker for en kamp hvor som helst i strengen.
re.treff ()
re.match () funksjon av re I Python vil søke det vanlige uttrykksmønsteret og returnere den første forekomsten. Python RegEx Match-metoden sjekker for en kamp bare i begynnelsen av strengen. Så, hvis en kamp er funnet i første linje, returnerer den kampobjektet. Men hvis en kamp er funnet i en annen linje, Returnerer Python RegEx Match-funksjonen null.
for eksempel, vurder Følgende Kode For Python re.match () – funksjonen. Uttrykket » w+» og «\w «vil matche ordene som begynner med bokstaven’ g ‘ og deretter, noe som ikke er startet med ‘g’ er ikke identifisert. For a sjekke kamp for hvert element i listen eller strengen, kjorer vi forloop i Denne Python re.match () Eksempel.

re.søk (): Finne Mønster i Tekst
re.søk () – funksjonen vil søke det regulære uttrykksmønsteret og returnere den første forekomsten. I motsetning Til Python re.match (), det vil sjekke alle linjene i inngangsstrengen. Den Python re.søk () – funksjonen returnerer et kampobjekt når mønsteret er funnet og» null » hvis mønsteret ikke er funnet
for å kunne bruke søk () – funksjonen må du først importere Python re-modulen og deretter utføre koden. Den Python re.søk () funksjonen tar «mønster» og «tekst» for å skanne fra vår hovedstreng
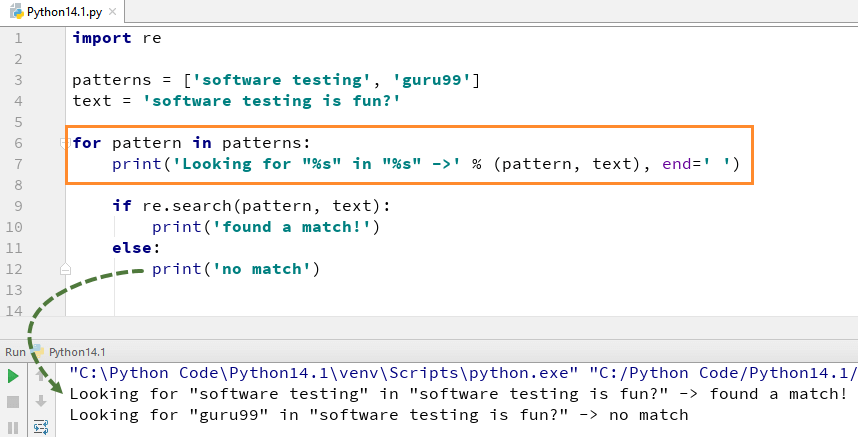
for eksempel her ser vi etter to bokstavelige strenger «Software testing «»guru99″, i en tekststreng»Software Testing is fun». For «software testing» fant vi kampen dermed returnerer utgangen Av Python re.søk () Eksempel som «funnet en kamp», mens for ordet» guru99 «vi ikke kunne finne i streng derfor returnerer utdataene som»ingen kamp».
re.findall ()
findall () modulen brukes til å søke etter» alle » forekomster som samsvarer med et gitt mønster. I kontrast vil search () – modulen bare returnere den første forekomsten som samsvarer med det angitte mønsteret. findall () vil iterere over alle linjene i filen og vil returnere alle ikke-overlappende treff av mønster i ett enkelt trinn.
For eksempel, her har vi en liste over e-postadresser, og vi vil at alle e-postadressene skal hentes ut fra listen, vi bruker metoden re.findall () I Python. Det vil finne alle e-postadressene fra listen.
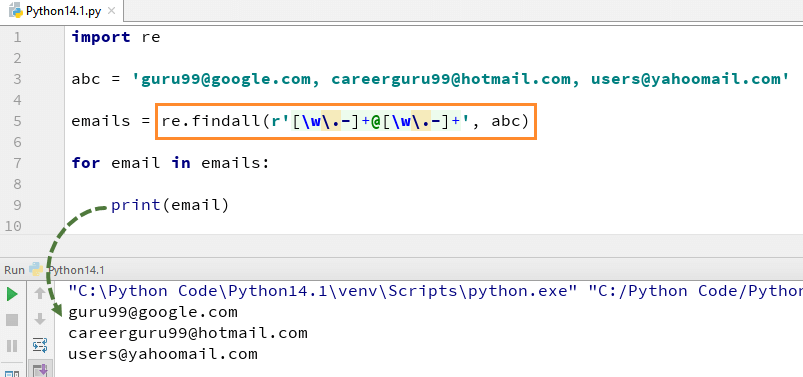
Her er den komplette koden for eksempel av re.findall()
import relist = for element in list: z = re.match("(g\w+)\W(g\w+)", element)if z: print((z.groups())) patterns = text = 'software testing is fun?'for pattern in patterns: print('Looking for "%s" in "%s" ->' % (pattern, text), end=' ') if re.search(pattern, text): print('found a match!')else: print('no match')abc = This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it.'emails = re.findall(r'+@+', abc)for email in emails: print(email)Python-Flagg
Mange Python Regex-Metoder og Regex-funksjoner tar et valgfritt argument kalt Flagg. Dette flagg kan endre betydningen av Den gitte Python Regex mønster. For å forstå Disse vil vi se ett eller to eksempel på Disse Flaggene.
Various flags used in Python includes
Syntax for Regex Flags What does this flag do Make begin/end consider each line It ignores case Make Make { \w,\W,\b,\B} follows Unicode rules Make {\w,\W,\b,\B} follow locale Allow comment in Regex Example of re.M Eller Flerline Flagg
i flerline mønsteret tegnet matche det første tegnet i strengen og begynnelsen av hver linje (følger umiddelbart etter hver ny linje). Mens uttrykket liten » w » brukes til å markere plassen med tegn. Når du kjører koden, skriver den første variabelen » k1 «bare ut tegnet» g » for word guru99, mens når du legger til multiline-flagg, henter den ut første tegn av alle elementene i strengen.
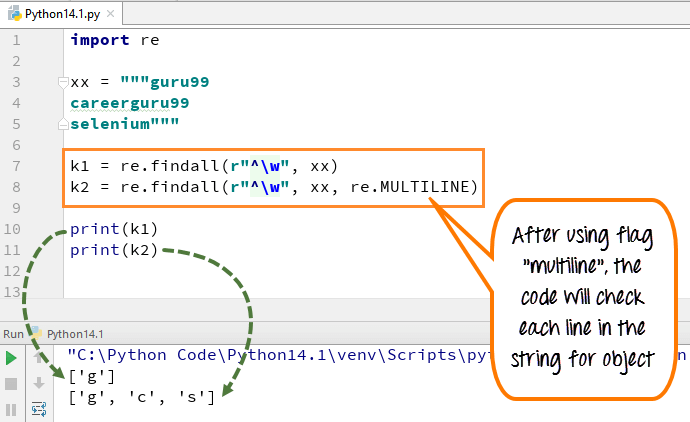
her er koden
import rexx = """guru99 careerguru99selenium"""k1 = re.findall(r"^\w", xx)k2 = re.findall(r"^\w", xx, re.MULTILINE)print(k1)print(k2)
- vi erklærte variabelen xx for streng » guru99…. careerguru99….selen «
- Kjør koden uten å bruke flags multiline, det gir utgangen bare ‘ g ‘ fra linjene
- Kjør koden med flagg «multiline», Når du skriver ut «k2», gir den utgangen som’ g’,’ c ‘og’ s ‘
- så forskjellen vi kan se etter og før du legger til flere linjer i eksemplet ovenfor.
På Samme måte kan du også bruke Andre Python-flagg som re.U (Unicode), re.L (Følg locale), re.X (Tillat Kommentar), etc.
Python 2 Eksempel
over koder Er Python 3 eksempler, hvis du vil kjøre I Python 2, vennligst vurder følgende kode.
# Example of w+ and ^ Expressionimport rexx = "guru99,education is fun"r1 = re.findall(r"^\w+",xx)print r1# Example of \s expression in re.split functionimport rexx = "guru99,education is fun"r1 = re.findall(r"^\w+", xx)print (re.split(r'\s','we are splitting the words'))print (re.split(r's','split the words'))# Using re.findall for textimport relist = for element in list: z = re.match("(g\w+)\W(g\w+)", element)if z: print(z.groups()) patterns = text = 'software testing is fun?'for pattern in patterns: print 'Looking for "%s" in "%s" ->' % (pattern, text), if re.search(pattern, text): print 'found a match!'else: print 'no match'abc = This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it., This email address is being protected from spambots. You need JavaScript enabled to view it.'emails = re.findall(r'+@+', abc)for email in emails: print email# Example of re.M or Multiline Flagsimport rexx = """guru99 careerguru99selenium"""k1 = re.findall(r"^\w", xx)k2 = re.findall(r"^\w", xx, re.MULTILINE)print k1print k2Sammendrag
et regulært uttrykk i et programmeringsspråk er en spesiell tekststreng som brukes til å beskrive et søkemønster. Det inkluderer sifre og tegnsetting og alle spesialtegn som$#@!%, osv. Uttrykk kan inkludere bokstavelig
- tekst matchende
- Repetisjon
- Forgrening
- Mønster-komposisjon etc.
I Python, er et regulært uttrykk betegnet SOM RE (REs, regexes eller regex mønster) er innebygd Gjennom Python re modul.
- «re» modul følger Med Python primært brukt for streng søking og manipulasjon
- også brukt ofte for webside «Skraping» (trekke ut store mengder data fra nettsteder)
- Regulære Uttrykk Metoder inkluderer re.match (), re.søk ()& re.findall ()
- Andre Python RegEx erstatte metoder er sub() og subn () som brukes til å erstatte matchende strenger i re
- Python Flagg Mange Python Regex Metoder og Regex funksjoner ta en valgfri argument kalt Flagg
Dette flaggene kan endre betydningen av den gitte Regex mønster
- Ulike Python flagg brukes I Regex Metoder er re.M, re.Jeg, re.S, etc.