BasicsEdit
În primul rând, unele vocabular:
| activare | = stat valoarea neuronului. Pentru neuronii binari, aceasta este de obicei 0 / 1 sau +1 / -1. |
| CAM | = conținut memorie adresabilă. Reamintind o memorie printr-un model parțial în loc de o adresă de memorie. |
| convergență | = stabilizarea unui model de activare într-o rețea. În SL, convergența înseamnă stabilizarea greutăților& prejudecăți mai degrabă decât activări. |
| discriminativ | = referitor la sarcinile de recunoaștere. Numită și analiză (în teoria modelelor) sau inferență. |
| energie | = o cantitate macroscopică care descrie modelul de activare într-o rețea. (a se vedea mai jos) |
| generalizare | = comportându-se cu precizie pe intrări ne-întâlnite anterior |
| generativ | = mașină imaginată și sarcină de rechemare. uneori numită sinteză (în teoria modelelor), mimică sau falsuri profunde. |
| inferență | = faza „run” (spre deosebire de formare). În timpul inferenței, rețeaua îndeplinește sarcina pe care este instruită să o facă—fie recunoașterea unui model (SL), fie crearea unuia (UL). De obicei, inferența coboară gradientul unei funcții energetice. Spre deosebire de SL, coborârea gradientului are loc în timpul antrenamentului, nu în inferență. |
| machine vision | = învățare automată pe imagini. |
| NLP | = procesarea limbajului Natural. Învățarea automată a limbilor umane. |
| pattern | = activări de rețea care au o ordine internă într-un anumit sens sau care pot fi descrise mai compact de caracteristicile din activări. De exemplu, modelul de pixeli al unui zero, indiferent dacă este dat ca date sau imaginat de rețea, are o caracteristică care poate fi descrisă ca o singură buclă. Caracteristicile sunt codificate în neuronii ascunși. |
| formare | = faza de învățare. Aici, rețeaua își ajustează greutățile & prejudecăți pentru a învăța din intrări. |
SARCINI

metodele UL pregătesc de obicei o rețea pentru sarcini generative, mai degrabă decât pentru recunoaștere, dar gruparea sarcinilor ca supravegheate sau nu poate fi neclară. De exemplu, recunoașterea scrierii de mână a început în anii 1980 ca SL. Apoi, în 2007, UL este folosit pentru a primi rețeaua pentru SL după aceea. În prezent, SL și-a recăpătat poziția de metodă mai bună.
instruire
în timpul fazei de învățare, o rețea nesupravegheată încearcă să imite datele pe care le-a dat și folosește eroarea în ieșirea sa mimată pentru a se corecta (de ex. greutățile sale& prejudecăți). Aceasta seamănă cu comportamentul mimetic al copiilor pe măsură ce învață o limbă. Uneori eroarea este exprimată ca o probabilitate scăzută ca ieșirea eronată să apară sau ar putea fi exprimată ca o stare instabilă de energie ridicată în rețea.
energie
o funcție energetică este o măsură macroscopică a stării unei rețele. Această analogie cu fizica este inspirată de analiza lui Ludwig Boltzmann a energiei macroscopice a unui gaz din probabilitățile microscopice ale mișcării particulelor p {\displaystyle \propto }

eE/kT, unde k este constanta Boltzmann și T este temperatura. În rețeaua RBM relația este P = e-E / Z, unde p & e variază în funcție de fiecare model de activare posibil și Z = A L L L P A t t E R n s {\displaystyle \sum _{AllPatterns}}

E-E(model). Pentru a fi mai precis, p(A) = e-E(A) / Z, unde a este un model de activare a tuturor neuronilor (vizibili și ascunși). Prin urmare, rețelele neuronale timpurii poartă numele de mașină Boltzmann. Paul Smolensky numește-E armonia. O rețea Caută energie scăzută, care este o armonie ridicată.
rețele
| Hopfield | Boltzmann | RBM | Helmholtz | Autoencoder | VAE |
|
 |
 restricted Boltzmann machine
|
 |

autoencoder
|
 autoencoder variațional |
|---|
Boltzmann și Helmholtz au venit înainte de formulările rețelelor neuronale, dar aceste rețele au împrumutat din analizele lor, astfel încât aceste rețele își poartă numele. Hopfield, cu toate acestea, a contribuit direct la UL.
Intermediatedit
aici, distribuțiile p(x) și q(X) vor fi prescurtate ca p și q.
History
| 1969 | Perceptrons by Minsky & Papert shows a perceptron without hidden layers fails on XOR |
| 1970s | (approximate dates) AI winter I |
| 1974 | Ising magnetic model proposed by WA Little for cognition |
| 1980 | Fukushima introduces the neocognitron, which is later called a convolution neural network. Este folosit mai ales în SL, dar merită o mențiune aici. |
| 1982 | varianta Ising Hopfield net descrisă ca came și clasificatoare de John Hopfield. |
| 1983 | Ising variantă mașină Boltzmann cu neuroni probabilistice descrise de Hinton& Sejnowski în urma Sherington& lui Kirkpatrick 1975 muncă. |
| 1986 | Paul Smolensky publică teoria armoniei, care este un RBM cu practic aceeași funcție energetică Boltzmann. Smolensky nu a oferit o schemă de pregătire practică. Hinton a făcut la mijlocul anilor 2000 |
| 1995 | Schmidthuber introduce neuronul LSTM pentru limbi. |
| 1995 | Dayan & Hinton introduces Helmholtz machine |
| 1995-2005 | (approximate dates) AI winter II |
| 2013 | Kingma, Rezende, & co. introduced Variational Autoencoders as Bayesian graphical probability network, with neural nets as components. |
Some more vocabulary:
| probabilitate | |
| CDF | = funcția de distribuție cumulativă. integrala pdf-ului. Probabilitatea de a se apropia de 3 este aria de sub curba cuprinsă între 2.9 și 3.1. |
| divergență contrastivă | = o metodă de învățare în care se scade energia pe modelele de antrenament și se ridică energia pe modelele nedorite din afara setului de antrenament. Acest lucru este foarte diferit de divergența KL, dar împărtășește o formulare similară. |
| valoare așteptată | = e(x) = x {\displaystyle \sum _{x}}
 x * p(X). Aceasta este valoarea medie sau valoarea medie. Pentru intrarea continuă x, înlocuiți însumarea cu o integrală. |
| variabilă latentă | = o cantitate neobservată care ajută la explicarea datelor observate. de exemplu, o infecție gripală (neobservată) poate explica de ce o persoană strănută (observată). În rețelele neuronale probabilistice, neuronii ascunși acționează ca variabile latente, deși interpretarea lor latentă nu este cunoscută în mod explicit. |
| = funcția de densitate de probabilitate. Probabilitatea ca o variabilă aleatoare să ia o anumită valoare. Pentru pdf continuu, p (3) = 1/2 poate însemna în continuare că există șanse aproape zero de a atinge această valoare exactă de 3. Raționalizăm acest lucru cu cdf. | |
| stochastic | = se comportă conform unei formule de densitate de probabilitate bine descrise. |
| Thermodynamics | |
| Boltzmann distribution | = Gibbs distribution. p ∝ {\displaystyle \propto }
eE/kT |
| entropy | = expected information = ∑ x {\displaystyle \sum _{x}}
p * log p |
| Gibbs free energy | = thermodynamic potential. Este munca maximă reversibilă care poate fi efectuată de un sistem de căldură la temperatură și presiune constantă. energie liberă g = căldură – temperatură * entropie |
| informații | = cantitatea de informații a unui mesaj x = -log p(x) |
| KLD | = entropie relativă. Pentru rețelele probabilistice, acesta este analogul erorii dintre intrarea & ieșire mimată. Divergența Kullback-Liebler (KLD) măsoară abaterea entropiei distribuției 1 de la o altă distribuție. KLD( p,q) = X {\displaystyle \sum _{x}}
p * log (p / q ). De obicei, p reflectă datele de intrare, q reflectă interpretarea rețelei, iar KLD reflectă diferența dintre cele două. |
Compararea rețelelor
| Hopfield | Boltzmann | RBM | Helmholtz | autoencoder | VAE | |
|---|---|---|---|---|---|---|
| utilizare ¬abili | cam, problema comis-voiajor | cam. Libertatea conexiunilor face ca această rețea să fie dificil de analizat. | recunoașterea modelului (MNIST, recunoașterea vorbirii) | imaginație, mimică | limbă: scriere creativă, traducere. Viziune: îmbunătățirea imaginilor neclare | generați date realiste |
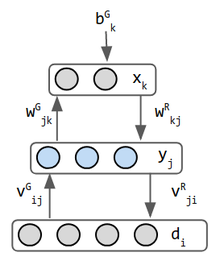
| neuron | stare binară deterministă. Activare = {0 (sau -1) dacă x este negativ, 1 altfel } | stocastic binar Hopfield neuron | stocastic binar. Extins la valoarea reală la mijlocul anilor 2000 | binar, sigmoid | limbă: LSTM. viziune: câmpuri receptive locale. de obicei, activarea relu reală. | |
| conexiuni | 1 strat cu greutăți simetrice. Fără auto-conexiuni. | 2 straturi. 1-ascuns & 1-vizibil. greutăți simetrice. | 2 straturi. greutăți simetrice. nu există conexiuni laterale într-un strat. | 3 straturi: greutăți asimetrice. 2 rețele combinate în 1. | 3 straturi. Intrarea este considerată un strat, chiar dacă nu are greutăți de intrare. straturi recurente pentru NLP. convoluții feedforward pentru viziune. intrare & ieșire au același număr de neuroni. | 3 straturi: intrare, encoder, distribuție sampler decodor. eșantionatorul nu este considerat un strat (e) |
| inferență & energie | energia este dată de măsura probabilității Gibbs : E = − 1 2 ∑ i , j w i j s i s j + ∑ m θ i s i {\displaystyle E=-{\frac {1}{2}}\sum _{i,j}{w_{ij}{s_{i}}{s_{j}}}+\sum _{i}{\theta _{i}}{s_{i}}}
 |
← aceeași | ← aceeași | a minimiza KL divergență | inferență este doar feed-forward. rețelele UL anterioare au rulat înainte și înapoi | minimizarea erorii = eroare de reconstrucție – KLD |
| formare | Inktwij = si*SJ, pentru +1/-1 neuron | Inktwij = e*(pij – p ‘ IJ). Acest lucru este derivat din minimizarea KLD. e = rata de învățare, p ‘ = prezisă și p = distribuția reală. | divergență contrastivă w/ Gibbs eșantionare | wake-sleep 2 faza de formare | înapoi propaga eroarea de reconstrucție | reparameterize stare ascunsă pentru backprop |
| puterea | seamănă cu sistemele fizice, astfel încât moștenește ecuațiile lor | <— la fel. neuronii ascunși acționează ca o reprezentare internă a lumii externe | mai rapidă schemă de formare mai practică decât mașinile Boltzmann | ușor anatomice. analizabil w/ teoria informației & mecanica statistică | ||
| slăbiciune | hopfield | greu de antrenat datorită conexiunilor laterale | RBM | Helmholtz |
rețele specifice
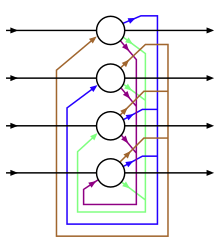
aici, evidențiem câteva caracteristici ale fiecărei rețele. Feromagnetismul a inspirat rețelele Hopfield, mașinile Boltzmann și RBM-urile. Un neuron corespunde unui domeniu de fier cu momente magnetice binare în sus și în jos, iar conexiunile neuronale corespund influenței domeniului unul asupra celuilalt. Conexiunile simetrice permit o formulare globală a energiei. În timpul inferenței, rețeaua actualizează fiecare stare utilizând funcția standard pas de activare. Greutățile simetrice garantează convergența către un model de activare stabil.rețelele Hopfield sunt folosite ca came și sunt garantate să se stabilească la un anumit model. Fără greutăți simetrice, rețeaua este foarte greu de analizat. Cu funcția energetică potrivită, o rețea va converge.
mașinile Boltzmann sunt plase stocastice Hopfield. Valoarea lor de stare este eșantionată din acest pdf după cum urmează: să presupunem că un neuron binar se declanșează cu probabilitatea Bernoulli p(1) = 1/3 și se sprijină cu p(0) = 2/3. Un eșantion din acesta luând un număr aleatoriu distribuit uniform y și conectându-l la funcția de distribuție cumulativă inversată, care în acest caz este funcția de pas pragată la 2/3. Funcția inversă = {0 dacă X<= 2/3, 1 Dacă x> 2/3}
mașinile Helmholtz sunt inspirații timpurii pentru codificatoarele auto variaționale. Este 2 rețele combinate în greutăți one-forward funcționează recunoaștere și greutăți înapoi pune în aplicare imaginația. Este probabil prima rețea care face ambele. Helmholtz nu a funcționat în învățarea automată, dar a inspirat punctul de vedere al „motorului de inferență statistică a cărui funcție este de a deduce cauzele probabile ale intrărilor senzoriale” (3). neuronul binar stocastic produce o probabilitate ca starea sa să fie 0 sau 1. Introducerea datelor nu este în mod normal considerată un strat, dar în modul de generare a mașinii Helmholtz, stratul de date primește intrarea din stratul mijlociu are greutăți separate în acest scop, deci este considerat un strat. Prin urmare, această rețea are 3 straturi.
Variational Autoencoder (VAE) sunt inspirate de mașini Helmholtz și combină rețeaua de probabilitate cu rețele neuronale. Un Autoencoder este o rețea cu came cu 3 straturi, unde stratul de mijloc ar trebui să fie o reprezentare internă a modelelor de intrare. Greutățile sunt denumite phi & theta mai degrabă decât W și V ca în Helmholtz—o diferență cosmetică. Rețeaua neuronală a codificatorului este o distribuție de probabilitate Q(Z|x), iar rețeaua de decodare este P(X|z). Aceste 2 rețele de aici pot fi conectate complet sau pot utiliza o altă schemă NN.
învățarea Hebbiană, arta, SOM
exemplul clasic de învățare nesupravegheată în studiul rețelelor neuronale este principiul lui Donald Hebb, adică neuronii care se aprind împreună sârmă împreună. În învățarea Hebbiană, conexiunea este întărită indiferent de o eroare, dar este exclusiv o funcție a coincidenței dintre potențialele de acțiune dintre cei doi neuroni. O versiune similară care modifică greutățile sinaptice ia în considerare timpul dintre potențialele de acțiune (plasticitate dependentă de spike-timing sau STDP). S-a emis ipoteza că învățarea hebbiană stă la baza unei game de funcții cognitive, cum ar fi recunoașterea tiparelor și învățarea experiențială.
printre modelele de rețele neuronale, harta auto-organizatoare (SOM) și teoria rezonanței adaptive (ART) sunt utilizate în mod obișnuit în algoritmii de învățare nesupravegheați. SOM este o organizație topografică în care locațiile din apropiere din hartă reprezintă intrări cu proprietăți similare. Modelul ART permite numărului de clustere să varieze în funcție de dimensiunea problemei și permite utilizatorului să controleze gradul de similitudine între membrii acelorași clustere prin intermediul unei constante definite de utilizator numită parametrul vigilență. Rețelele ART sunt utilizate pentru multe sarcini de recunoaștere a modelelor, cum ar fi recunoașterea automată a țintei și procesarea semnalului seismic.