recunoașterea feței — pas cu pas
să abordăm această problemă pas cu pas. Pentru fiecare pas, vom afla despre un algoritm diferit de învățare automată. Nu voi explica complet fiecare algoritm pentru a împiedica acest lucru să se transforme într-o carte, dar veți învăța ideile principale din spatele fiecăruia și veți afla cum vă puteți construi propriul sistem de recunoaștere facială în Python folosind OpenFace și dlib.
Pasul 1: Găsirea tuturor fețelor
primul pas în conducta noastră este detectarea feței. Evident, avem nevoie pentru a localiza fețele într-o fotografie înainte de a putea încerca să le spun în afară!
dacă ați folosit vreo cameră în ultimii 10 ani, probabil ați văzut detectarea feței în acțiune:

detectarea feței este o caracteristică excelentă pentru camere. Când camera poate alege automat fețele, se poate asigura că toate fețele sunt focalizate înainte de a face fotografia. Dar o vom folosi pentru un scop diferit-găsirea zonelor imaginii pe care dorim să le transmitem la următorul pas din conducta noastră.
detectarea feței a devenit populară la începutul anilor 2000, când Paul Viola și Michael Jones au inventat o modalitate de a detecta fețele care era suficient de rapidă pentru a rula pe camere ieftine. Cu toate acestea, acum există soluții mult mai fiabile. Vom folosi o metodă inventată în 2005 numită histograma gradienților orientați — sau pur și simplu porc pe scurt.
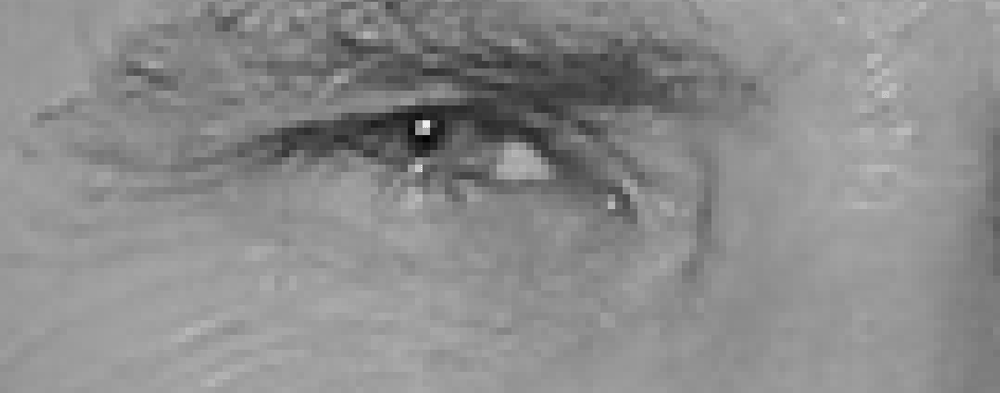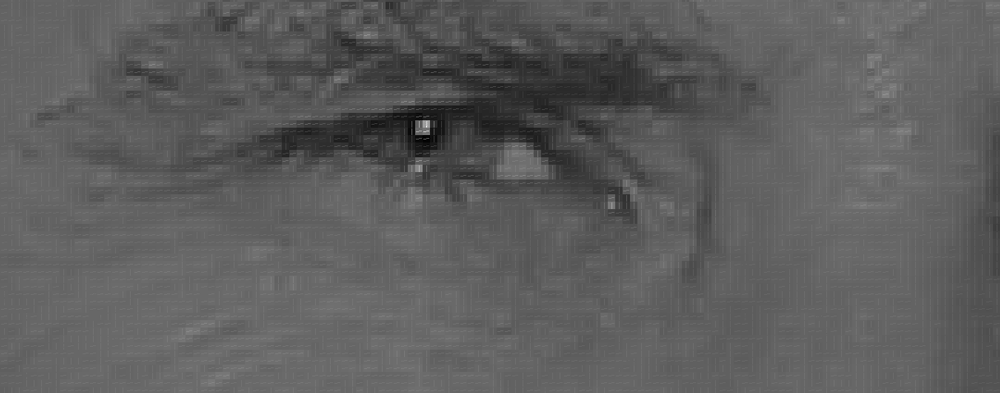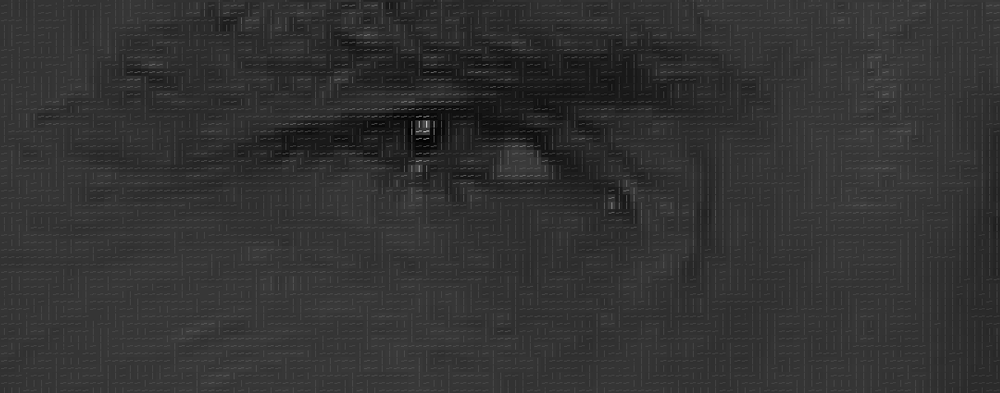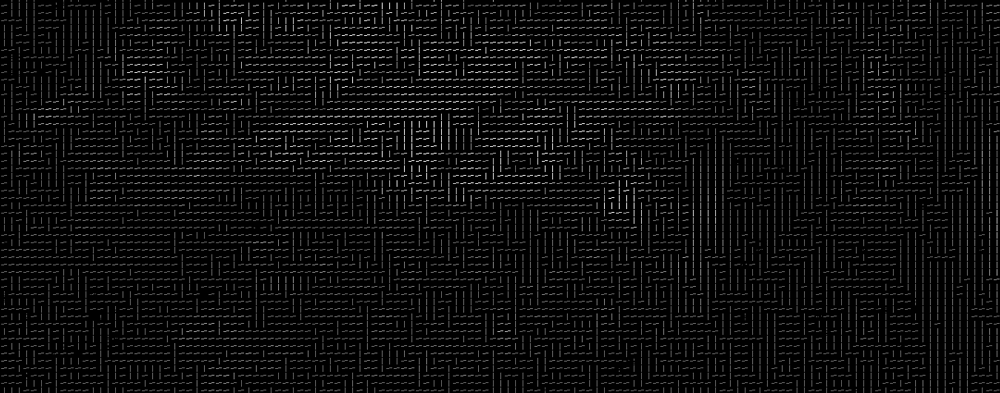
pentru a găsi fețe într-o imagine, vom începe prin a face imaginea noastră alb-negru, deoarece nu avem nevoie de date de culoare pentru a găsi fețe:

apoi ne vom uita la fiecare pixel din imaginea noastră unul câte unul. Pentru fiecare pixel, vrem să ne uităm la pixelii care îl înconjoară direct:

scopul nostru este să ne dăm seama cât de întunecat este pixelul curent în comparație cu pixelii care îl înconjoară direct. Apoi vrem să desenăm o săgeată care arată în ce direcție imaginea devine mai întunecată:

privind doar acest pixel și pixelii atingându-l, imaginea se întunecă spre dreapta sus.
dacă repetați acest proces pentru fiecare pixel din imagine, veți ajunge ca fiecare pixel să fie înlocuit cu o săgeată. Aceste săgeți sunt numite gradienți și arată fluxul de la lumină la întuneric pe întreaga imagine:
acest lucru ar putea părea un lucru aleatoriu de făcut, dar există un motiv foarte bun pentru înlocuirea pixelilor cu gradienți. Dacă analizăm direct pixelii, imaginile cu adevărat întunecate și imaginile cu adevărat ușoare ale aceleiași persoane vor avea valori de pixeli total diferite. Dar luând în considerare doar direcția în care se schimbă luminozitatea, atât imaginile cu adevărat întunecate, cât și imaginile cu adevărat luminoase vor ajunge la aceeași reprezentare exactă. Acest lucru face ca problema să fie mult mai ușor de rezolvat!
dar salvarea gradientului pentru fiecare pixel ne oferă prea multe detalii. Ajungem să pierdem pădurea pentru copaci. Ar fi mai bine dacă am putea vedea fluxul de bază al luminozității/întunericului la un nivel superior, astfel încât să putem vedea modelul de bază al imaginii.
pentru a face acest lucru, vom împărți imaginea în pătrate mici de 16×16 pixeli fiecare. În fiecare pătrat, vom număra câte gradienți indică în fiecare direcție majoră (câte puncte în sus, în sus-dreapta, în dreapta, etc…). Apoi vom înlocui acel pătrat din imagine cu direcțiile săgeții care au fost cele mai puternice.
rezultatul final este că transformăm imaginea originală într-o reprezentare foarte simplă care surprinde structura de bază a unei fețe într-un mod simplu:

pentru a găsi fețe în această imagine de porc, tot ce trebuie să facem este să găsim partea din imaginea noastră care arată cel mai asemănător cu un model de porc cunoscut care a fost extras dintr-o grămadă de alte fețe de antrenament:

folosind această tehnică, acum putem găsi cu ușurință fețe în orice imagine:

dacă doriți să încercați acest pas singur folosind Python și dlib, iată codul care arată cum să generați și să vizualizați reprezentările Hog ale imaginilor.
Pasul 2: pozarea și proiectarea fețelor
Whew, am izolat fețele din imaginea noastră. Dar acum avem de a face cu problema care se confruntă transformat direcții diferite arata total diferit la un calculator:

oamenii pot recunoaște cu ușurință că ambele imagini sunt ale lui Will Ferrell, dar computerele ar vedea aceste imagini ca două persoane complet diferite.
pentru a explica acest lucru, vom încerca să deformăm fiecare imagine, astfel încât ochii și buzele să fie întotdeauna în eșantionul din imagine. Acest lucru ne va face mult mai ușor să comparăm fețele în pașii următori.pentru a face acest lucru, vom folosi un algoritm numit face landmark estimation. Există o mulțime de modalități de a face acest lucru, dar vom folosi abordarea inventată în 2014 de Vahid Kazemi și Josephine Sullivan.
ideea de bază este că vom veni cu 68 de puncte specifice (numite repere) care există pe fiecare față — partea superioară a bărbiei, marginea exterioară a fiecărui ochi, marginea interioară a fiecărei sprâncene etc. Apoi vom instrui un algoritm de învățare automată pentru a putea găsi aceste 68 de puncte specifice pe orice față:

cele 68 de repere pe care le vom localiza pe fiecare față. Această imagine a fost creată de Brandon Amos de la CMU care lucrează la OpenFace.
iată rezultatul localizării celor 68 de repere ale feței pe imaginea noastră de testare:

acum că știm că ochii și gura sunt, vom roti, scala și forfeca imaginea, astfel încât ochii și gura să fie centrate cât mai bine posibil. Nu vom face nicio deformare 3D fantezistă, deoarece asta ar introduce distorsiuni în imagine. Vom folosi doar transformări de bază ale imaginii, cum ar fi rotația și scara, care păstrează liniile paralele (numite transformări afine):

acum, indiferent de modul în care se întoarce fața, suntem capabili să centrăm ochii și gura sunt în aproximativ aceeași poziție în imagine. Acest lucru va face următorul pas mult mai precis.
dacă doriți să încercați acest pas singur folosind Python și dlib, iată codul pentru găsirea reperelor feței și iată codul pentru transformarea imaginii folosind acele repere.
Pasul 3: Codificarea fețelor
acum suntem la carnea problemei — de fapt, spunând fețele în afară. Aici lucrurile devin cu adevărat interesante!
cea mai simplă abordare a recunoașterii feței este de a compara direct fața necunoscută pe care am găsit-o la Pasul 2 cu toate imaginile pe care le avem cu oameni care au fost deja etichetați. Când găsim o față etichetată anterior care arată foarte asemănătoare cu fața noastră necunoscută, trebuie să fie aceeași persoană. Pare o idee destul de bună, nu?
există de fapt o mare problemă cu această abordare. Un site precum Facebook cu miliarde de utilizatori și un trilion de fotografii nu poate trece prin fiecare față etichetată anterior pentru a o compara cu fiecare imagine recent încărcată. Asta ar dura prea mult. Ei trebuie să poată recunoaște fețele în milisecunde, nu în ore.
avem nevoie de o modalitate de a extrage câteva măsurători de bază de pe fiecare față. Apoi am putea măsura fața noastră necunoscută în același mod și să găsim fața cunoscută cu cele mai apropiate măsurători. De exemplu, am putea măsura dimensiunea fiecărei urechi, distanța dintre ochi, lungimea nasului etc. Dacă ați urmărit vreodată un spectacol de crimă rău ca CSI, știi ce vorbesc despre:
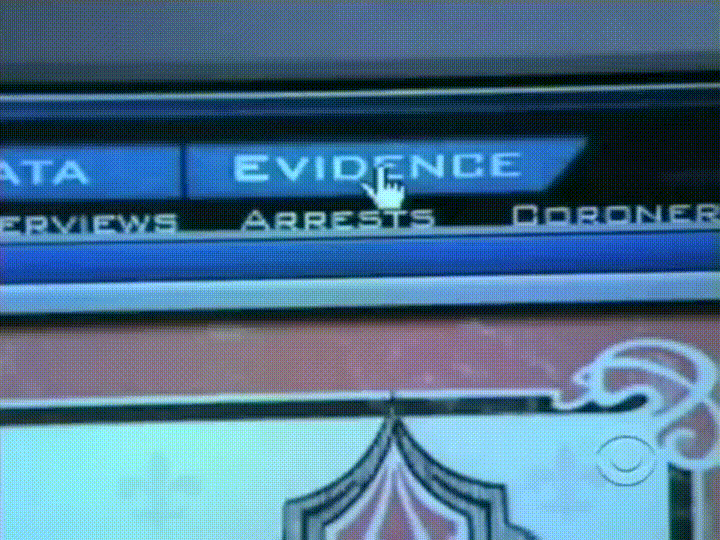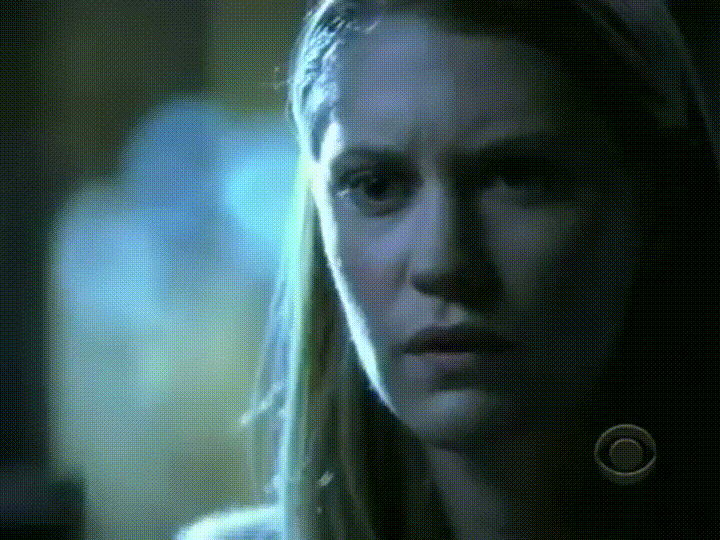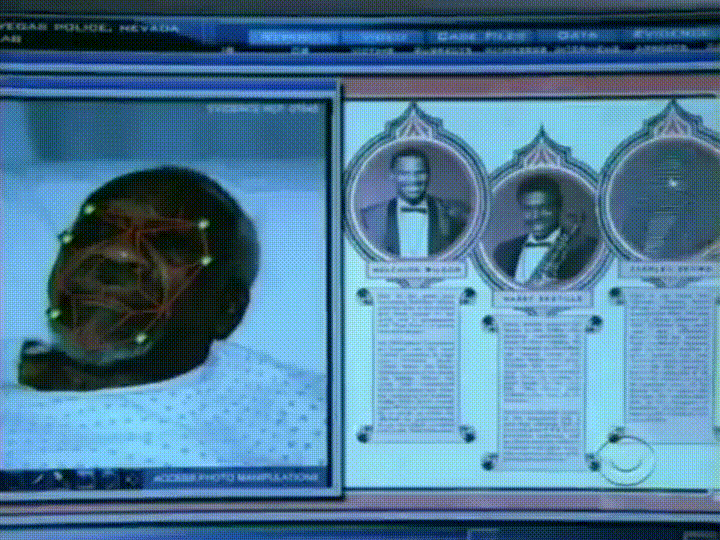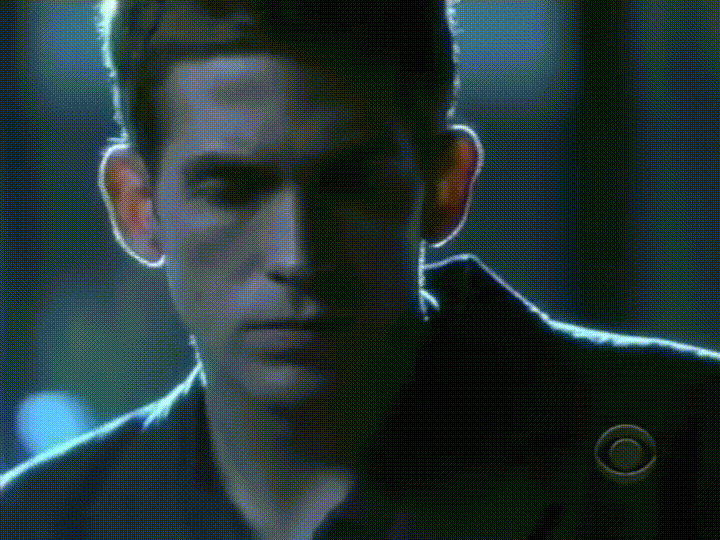
cel mai fiabil mod de a măsura o față
Ok, deci ce măsurători ar trebui să colectăm de la fiecare față pentru a construi baza noastră de date cunoscută? Mărimea urechii? Lungimea nasului? Culoarea ochilor? Altceva?
se pare că măsurătorile care par evidente pentru noi oamenii (cum ar fi culoarea ochilor) nu au sens pentru un computer care se uită la pixeli individuali dintr-o imagine. Cercetătorii au descoperit că cea mai precisă abordare este de a lăsa computerul să-și dea seama de măsurători pentru a se colecta. Învățarea profundă face o treabă mai bună decât oamenii în a afla ce părți ale feței sunt importante de măsurat.
soluția este de a instrui o rețea neuronală convoluțională profundă (la fel cum am făcut în partea 3). Dar, în loc să antrenăm rețeaua să recunoască obiectele pictures așa cum am făcut ultima dată, o vom antrena pentru a genera 128 de măsurători pentru fiecare față.
procesul de instruire funcționează uitându-se la 3 imagini ale feței la un moment dat:
- încărcați o imagine a feței de antrenament a unei persoane cunoscute
- încărcați o imagine a aceleiași persoane cunoscute
- încărcați o imagine a unei persoane total diferite
apoi algoritmul analizează măsurătorile pe care le generează în prezent pentru fiecare dintre aceste trei imagini. Apoi ajustează ușor rețeaua neuronală, astfel încât să se asigure că măsurătorile pe care le generează pentru #1 și #2 sunt puțin mai apropiate, asigurându-se în același timp că măsurătorile pentru #2 și #3 sunt puțin mai îndepărtate:

după repetarea acestui pas de milioane de ori pentru milioane de imagini a mii de oameni diferiți, rețeaua neuronală învață să genereze în mod fiabil 128 de măsurători pentru fiecare persoană. Orice zece imagini diferite ale aceleiași persoane ar trebui să dea aproximativ aceleași măsurători.
oamenii de învățare automată numesc cele 128 de măsurători ale fiecărei fețe o încorporare. Ideea de a reduce datele brute complicate, cum ar fi o imagine, într-o listă de numere generate de computer, apare foarte mult în învățarea automată (în special în traducerea limbilor). Abordarea exactă a fețelor pe care le folosim a fost inventată în 2015 de cercetătorii de la Google, dar există multe abordări similare.
codarea imaginii feței noastre
acest proces de instruire a unei rețele neuronale convoluționale pentru a afișa încorporări ale feței necesită o mulțime de date și putere computerizată. Chiar și cu o placă video NVidia Telsa scumpă, este nevoie de aproximativ 24 de ore de pregătire continuă pentru a obține o precizie bună.
dar odată ce rețeaua a fost instruită, poate genera măsurători pentru orice față, chiar și pentru cele pe care nu le-a mai văzut până acum! Deci, acest pas trebuie făcut o singură dată. Din fericire pentru noi, cei buni de la OpenFace au făcut deja acest lucru și au publicat mai multe rețele instruite pe care le putem folosi direct. Multumesc Brandon Amos și echipa!deci, tot ce trebuie să facem noi înșine este să rulăm imaginile feței noastre prin rețeaua lor pre-instruită pentru a obține cele 128 de măsurători pentru fiecare față. Iată măsurătorile pentru imaginea noastră de testare:

deci, ce părți ale feței măsoară exact aceste 128 de numere? Se pare că nu avem nicio idee. Nu prea contează pentru noi. Tot ce ne pasă este că rețeaua generează aproape aceleași numere atunci când se uită la două imagini diferite ale aceleiași persoane.
Dacă doriți să încercați singur acest pas, OpenFace oferă un script lua care va genera încorporări toate imaginile într-un folder și le va scrie într-un fișier csv. O conduci așa.
Pasul 4: găsirea numelui persoanei din codificarea
acest ultim pas este de fapt cel mai simplu pas din întregul proces. Tot ce trebuie să facem este să găsim persoana din Baza noastră de date cu persoane cunoscute care are cele mai apropiate măsurători de imaginea noastră de testare.
puteți face acest lucru folosind orice algoritm de clasificare a învățării automate de bază. Nu sunt necesare trucuri fanteziste de învățare profundă. Vom folosi un clasificator SVM liniar simplu, dar o mulțime de algoritmi de clasificare ar putea funcționa.tot ce trebuie să facem este să instruim un clasificator care poate lua măsurătorile dintr-o nouă imagine de test și să spună care persoană cunoscută este cea mai apropiată potrivire. Rularea acestui clasificator durează milisecunde. Rezultatul Clasificatorului este numele persoanei!
deci, să încercăm sistemul nostru. În primul rând, am pregătit un clasificator cu încorporările a aproximativ 20 de imagini fiecare dintre Will Ferrell, Chad Smith și Jimmy Falon: