
în acest tutorial, veți învăța regresia logistică. Aici veți ști exact ce este regresia logistică și veți vedea, de asemenea, un exemplu cu Python. Regresia logistică este un subiect important al învățării automate și voi încerca să o fac cât mai simplă posibil.
la începutul secolului al XX-lea, regresia logistică a fost folosită în principal în biologie după aceasta, a fost utilizată în unele aplicații de științe Sociale. Dacă sunteți curioși, vă puteți întreba unde ar trebui să folosim regresia logistică? Deci folosim regresia logistică atunci când variabila noastră independentă este categorică.
Exemple:
- pentru a prezice dacă o persoană va cumpăra o mașină (1) sau (0)
- pentru a ști dacă tumora este malignă (1) sau (0)
acum, să luăm în considerare un scenariu în care trebuie să clasificați dacă o persoană va cumpăra o mașină sau nu. În acest caz, dacă folosim regresia liniară simplă, va trebui să specificăm un prag pe care se poate face clasificarea.
să spunem că clasa reală este persoana care va cumpăra mașina, iar valoarea continuă prezisă este de 0,45, iar pragul pe care l-am considerat este 0.5, atunci acest punct de date vor fi considerate ca persoana nu va cumpara masina si acest lucru va duce la predicție greșită.
deci concluzionăm că nu putem folosi regresia liniară pentru acest tip de problemă de clasificare. După cum știm regresia liniară este delimitată, Deci aici vine regresia logistică unde valoarea variază strict de la 0 la 1.
regresie logistică simplă:
ieșire: 0 sau 1
ipoteză: K = W * X + B
H(x) = sigmoid(K)
funcția Sigmoid:


tipuri de regresie logistică:
regresie logistică binară
doar două rezultate posibile(Categorie).
exemplu: persoana va cumpăra o mașină sau nu.
regresie logistică multinomială
Mai mult de două categorii posibile fără ordonare.
regresie logistică ordinală
Mai mult de două categorii posibile cu ordonarea.
exemplu din lumea reală cu Python:
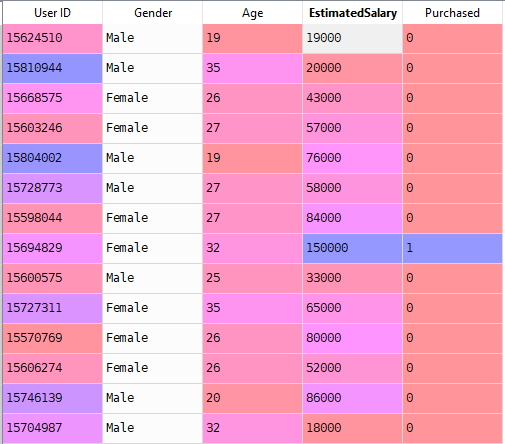
acum vom rezolva o problemă din lumea reală cu regresia logistică. Avem un set de date având 5 coloane și anume: User ID, sex, vârstă, EstimatedSalary și achiziționate. Acum trebuie să construim un model care să poată prezice dacă pe parametrul dat o persoană va cumpăra o mașină sau nu.
pași pentru a construi modelul:
1. Importing the libraries
aici vom importa biblioteci care vor fi necesare pentru a construi modelul.
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd2. Importing the Data set
vom importa setul nostru de date într-o variabilă (adică set de date) folosind Panda.
dataset = pd.read_csv('Social_Network_Ads.csv')3. Splitting our Data set in Dependent and Independent variables.
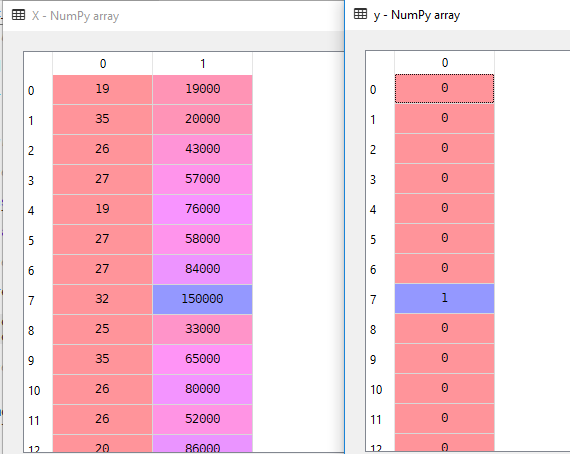
în setul nostru de date vom considera vârsta și estimatsalary ca variabilă independentă și achiziționate ca variabilă dependentă.
X = dataset.iloc].valuesy = dataset.iloc.valuesaici X este variabilă independentă și y este variabilă dependentă.
3. Splitting the Data set into the Training Set and Test Set
acum vom împărți setul nostru de date în date de antrenament și date de testare. Datele de instruire vor fi utilizate pentru a instrui modelul nostru Logistic, iar datele de testare vor fi utilizate pentru a valida modelul nostru. Vom folosi Sklearn pentru a împărți datele noastre. Vom importa train_test_split din sklearn.model_selection
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
4. Feature Scaling
acum vom face scalarea caracteristicilor pentru a scala datele noastre între 0 și 1 pentru a obține o precizie mai bună.
aici scalarea este importantă, deoarece există o diferență uriașă între vârstă și EstimatedSalay.
- importați StandardScaler de la sklearn.preprocesare
- apoi faceți o instanță sc_X a obiectului StandardScaler
- apoi potriviți și transformați x_train și transformați x_test
from sklearn.preprocessing import StandardScalersc_X = StandardScaler()X_train = sc_X.fit_transform(X_train)X_test = sc_X.transform(X_test)
5. Fitting Logistic Regression to the Training Set
acum vom construi clasificatorul nostru (logistic).
- import LogisticRegression de la sklearn.linear_model
- face un clasificator instanță a obiectului LogisticRegression și să dea
random_state = 0 pentru a obține același rezultat de fiecare dată. - acum utilizați acest clasificator pentru a se potrivi X_train și y_train
from sklearn.linear_model import LogisticRegressionclassifier = LogisticRegression(random_state=0)classifier.fit(X_train, y_train)noroc!! După executarea comenzii de mai sus veți avea un clasificator care poate prezice dacă o persoană va cumpăra o mașină sau nu.
acum utilizați clasificatorul pentru a face predicția pentru setul de date de testare și pentru a găsi precizia folosind matricea de confuzie.
6. Predicting the Test set results
y_pred = classifier.predict(X_test)acum vom primi y_pred

acum putem folosi y_test (rezultatul real) și y_pred ( rezultatul prezis) pentru a obține acuratețea modelului nostru.
7. Making the Confusion Matrix
folosind matricea de confuzie putem obține acuratețea modelului nostru.
from sklearn.metrics import confusion_matrixcm = confusion_matrix(y_test, y_pred)veți obține o matrice cm .

utilizați cm pentru a calcula precizia așa cum se arată mai jos:
Accuracy = ( cm + cm) /(Total test data points)

aici obținem o precizie de 89 % . Noroc!! obținem o precizie bună.
în cele din urmă, vom vizualiza rezultatul setului de antrenament și rezultatul setului de teste. Vom folosi matplotlib pentru a trasa setul nostru de date.
vizualizarea rezultatului setului de antrenament
from matplotlib.colors import ListedColormapX_set, y_set = X_train, y_trainX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Training set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()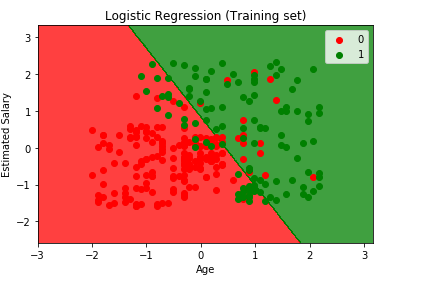
vizualizarea rezultatului setului de testare
from matplotlib.colors import ListedColormapX_set, y_set = X_test, y_testX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Test set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()
acum vă puteți construi propriul clasificator pentru regresie logistică.
Multumesc!! Continuă Să Codifici !!
Notă: Aceasta este o postare de invitat, iar opinia din acest articol este a scriitorului invitat. Dacă aveți probleme cu oricare dintre articolele postate pe www.marktechpost.com please contact at [email protected]
Advertisement
