În acest articol, vom învăța cum să folosim operatorul SQL LIKE, în SQL Server, folosind expresii regulate pentru a găsi și/sau manipula textul. Vom începe prin a învăța simbolurile și sintaxa de bază a utilizării expresiilor regulate wildcard. Vom folosi seturi de caractere și expresii de repetiție pentru a crea modele de potrivire flexibile și, pe parcurs, vom examina diferite moduri de a utiliza operatorul similar. Și apoi, în cele din urmă, în ultima parte a secțiunii, vom explora unele dintre cele mai comune și mai utile exemple de expresie regulată.
SQL este limbajul cel mai frecvent utilizat pentru a lucra cu baze de date. Când proiectați un raport sau utilizați BI sau orice instrument de raportare, software-ul construiește aproape sigur o interogare SQL în spatele scenei care rulează pe baza de date și returnează datele selectate. Când căutăm date specifice sau date care corespund unor criterii specifice, clauza where furnizează setul de instrumente de care aveți nevoie. Aceasta oferă o opțiune de interogare a anumitor rânduri pe care le căutăm în locul întregului tabel.
Pre-requisites
Descărcați baza de date AdventureWorks2014 aici pentru a testa următoarele probe T-SQL.
Noțiuni de bază
să parcurgem instrucțiunile SQL folosind cuvinte cheie similare și caractere wildcard. Deci, să începem să învățăm despre SQL ca operator.
folosind SQL ca exemple de caractere Wildcard
expresiile regulate sunt modele pentru a descrie modul de potrivire a șirurilor într-o clauză WHERE. Multe limbaje de programare acceptă expresii regulate care utilizează o sintaxă ușor diferită de cea utilizată cu operatorul similar. În acest articol, când ne referim la expresii regulate, ne referim la modelele utilizate cu SQL ca operatorul
tabelul următor include patru caractere diferite wildcard. De asemenea, puteți consulta articolul SQL string functions for Data Munging (Wrangling) pentru mai multe exemple.
|
Caractere Wildcard |
descriere |
% |
orice șir cu zero sau mai multe caractere în modelul de căutare |
|
orice căutare de un singur caracter cu modelul specificat |
orice căutare de un singur caracter în intervalul specificat |
folosind SQL ca cu ” % ” caracter wildcard
următoarele Instrucțiunea SQL returnează toate rândurile de tabel persoană în cazul în care numele lor începe cu litera A. să ne specifica litera ‘A’, Primul caracter care trebuie să fie în șir și apoi utilizați wildcard ‘%’, procentul.
|
1
2
3
|
selectați top 10 *
de la persoană.Persoana
unde prenume ca’A%’;
|
veți vedea ieșirea care listează primele 10 rânduri ale tabelului de persoane în care primul nume începe cu A și restul caracterului este necunoscut.

folosind SQL ca cu caracterul wildcard ‘ _ ‘
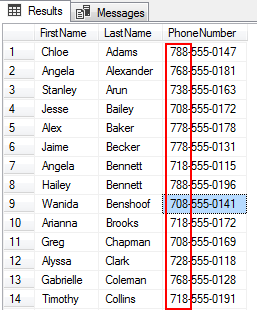
wildcard, subliniere, este pentru potrivire orice caracter unic. Următoarea Instrucțiune SQL găsește toate numerele de telefon care au un cod de zonă începând cu 7 și terminând cu 8 în coloana phonenumber. Am inclus, de asemenea, caracterul % wildcard la sfârșitul modelului de căutare, deoarece nu suntem preocupați de restul valorilor șirului.
|
1
2
3
4
5
6
7
|
selectați p.firstname,
p.lastname,
phonenumber
de la persoană.PersonPhone ca ph
interior se alăture persoană.Persoană ca p pe ph. BusinessEntityID = p.BusinessEntityID
unde Ph.PhoneNumber ca ‘7_8%’
ordine de p.LastName;
|
ieșirea arată că codul de zonă care începe cu 7 și se termină cu 8 sunt listate.
folosind SQL ca și cu caracterele wildcard
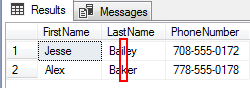
paranteze pătrate, de exemplu, ne permit să identificăm mai multe caractere unice care ar fi în acea poziție particulară. De exemplu, să spunem să enumerăm toate rândurile în care primele nume al treilea caracter începe cu I sau K. În loc să scriem mai multe condiții asemănătoare, putem plasa setul de potrivire a modelului în a treia poziție și îl putem închide în pătrat. Motorul de interogare caută mai întâi ‘I’ și apoi caută ‘K’.
să executăm următoarea Instrucțiune SQL
|
1
2
3
4
5
6
7
|
selectați p.prenume,
p.Numele de familie,
Numărul de telefon
de la persoană.PersonPhone ca ph
interior se alăture persoană.Persoană ca p pe ph.BusinessEntityID = P.BusinessEntityID
unde Ph.PhoneNumber ca ‘7_8%’ și p.lastname ca ‘Ba%’
ordine de p.LastName;
|
interogarea de mai sus poate fi re-scris folosind sau condiție. Este mai mult ca o condiție sau.
|
1
2
3
4
5
6
7
|
selectați p.prenume,
p.nume,
phonenumber
de la persoana.PersonPhone ca ph
interior se alăture persoană.Persoană ca p pe ph.BusinessEntityID = p.BusinessEntityID
unde ph.PhoneNumber ca ‘7_8%’ și (p.lastname ca ‘Bai%’ sau p.LastName CA ‘Bak%’)
ordine de p.LastName;
|
În ieșire, putem vedea că numele de familie în cazul în care al treilea caracter este”I”sau”k”sunt listate
folosind SQL ca cu caracterul wildcard ‘ ^ ‘
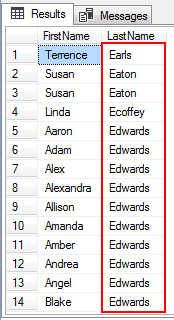
următoarea instrucțiune SQL afișează toate rândurile care nu au litera care începe cu A la D în primul caracter al numelui lor de familie. Pentru a plasa caracterul tilde în prima poziție a modelului. Ea devine nu premisele.
|
1
2
3
4
5
|
selectați p.firstname,
p.LastName
de la persoană.Persoana p
unde numele de familie ca ‘ % ‘
comanda dupa p. numele de familie;
|
acum, dacă rulez interogarea de mai sus, vom vedea că toate Numele care revin nu au un A, B, C sau D ca primul lor caracter.
folosind SQL nu ca cu caracterele wildcard
următoarea Instrucțiune SQL găsește toate persoanele în care coloana prenume are mai mult de 3 caractere.
|
1
2
3
4
|
selectați distinct
prenume
de la persoană.Persoana
unde firstname nu ca „;
|
lista de ieșire numai acele nume în cazul în care lungimea primului nume este mai mare de 3

folosind SQL ca cu clauza de evacuare
în următoarea instrucțiune SQL, clauza de evacuare este folosit pentru a scăpa de caracterul ‘!’pentru a nega sensul’ % ‘Pentru a găsi șirul’ 100% liber ‘ în coloana col1 a tabelului temp.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
DROP TABLE IF EXISTS temp;
CREATE TABLE temp(col1 VARCHAR(100));
GO
INSERT INTO temp
VALUES(‘ApexSQL Refactor is 100% Free SQL Formatter tool’), (‘ApexSQL Job is 10-15% off today only’);
du-te
selectați *
din TEMP;
selectați *
din temp
unde col1 ca ‘%100!% Gratuit % ‘ESCAPE’!’;
GO
|
lista de ieșire numai acele valori în cazul în care modelul de căutare „100% Liber” se potrivește cu expresia col1.

folosind SQL ca cu instrucțiunea CASE
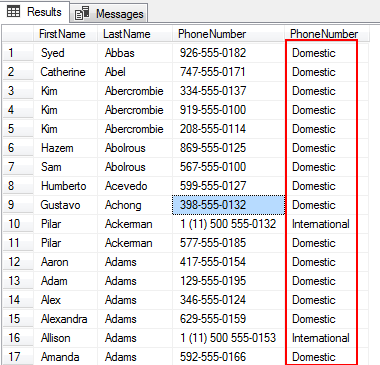
următoarea Instrucțiune SQL scoate toți angajații care au un număr de telefon formatat ca trei-trei-patru cifre cu liniuțe între (999-999-9999). Modelul este apoi comparat cu coloana phonenumber pentru a obține categoriile interne sau internaționale.
expresia cazului este evaluată pentru modelul specific pentru a obține tipul categoriei de telefon.
|
1
2
3
4
5
6
7
8
9
|
selectați p.prenume,
p.nume,
phonenumber,
caz când pH.phonenumber ca ‘ – ‘ apoi ‘numărul de telefon intern’
else ‘numărul de telefon internațional’
India phonenumber
de la persoana.PersonPhone ca ph
interior se alăture persoană.Persoană ca p pe ph. BusinessEntityID = P.BusinessEntityID
comanda de p.LastName;
|
În ieșire, putem vedea numărul este clasificat ca intern sau internațional. Coloana phonenumber este evaluată cu operatorul LIKE folosind suportul pătrat. Numărul de la zero la nouă în prima poziție de caractere este evaluat pentru potrivirea modelului de la zero la nouă, orice număr de la zero la nouă în a doua poziție de caractere și a treia și apoi a patra poziție de caractere trebuie să fie o liniuță și o logică similară se aplică restului caracterelor.
folosind SQL ca cu SQL dinamic
următoarea Instrucțiune SQL returnează toți angajații în cazul în care lastname se potrivește cu modelul Barb. Modelul este creat dinamic și comparat cu expresia.
|
1
2
3
4
5
6
7
|
precizând @elastname varchar(20)= ‘Barb’;
selectați p.firstname,
p.lastname,
os.Oraș
de la persoana.Persoană p
Alăturați-vă persoanei.Adresa pe P. BusinessEntityID = ‘s. AddressID
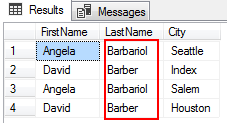
unde p. LastName ca’ %’+ @ ELastName+’%’;
|
lista de ieșire rândurile potrivite pentru modelul specificat Barb
notă: în mod implicit, char injectează spații libere în funcție de lungimea câmpului. Utilizați RTRIM pentru a suprima spațiile libere, dacă utilizați tipul de date char.
în următoarea Instrucțiune SQL, câmpul @eLastName este de tip de date char. Puteti vedea o utilizare a funcției RTRIM să tăiați semifabricatele la final.
|
1
2
3
4
5
6
7
|
precizând @elastname char(20)= ‘Barb’;
selectați p.firstname,
p.lastname,
la.Oraș
de la persoana.Persoană p
Alăturați-vă persoanei.Adresa pe p. BusinessEntityID = ‘s. AddressID
unde p. LastName ca’ % ‘ +RTRIM (@ELastName)+’%’;
|
folosind SQL ca cu o instrucțiune IF
următoarea Instrucțiune SQL, valoarea de intrare este evaluată pentru modelul specific din clauza condiție folosind instrucțiunea IF.
|
1
2
3
4
5
|
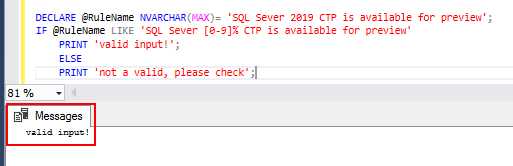
declara @rulename nvarchar(max)= ‘SQL Sever 2019 CTP este disponibil pentru previzualizare’;
dacă @ RuleName ca ‘SQL Sever % CTP este disponibil pentru previzualizare’
PRINT ‘ intrare validă bun!’;
ELSE
PRINT ‘ nu este un bun valid!’;
|
șirul de intrare este evaluat pentru modele specifice folosind SQL ca expresie wildcard și returnează șir de intrare valid.
asta e tot pentru moment!
rezumat
până în prezent, am discutat diverse sfaturi și patru metacaractere diferite (%,_,, și ^] care sunt disponibile cu operatorul SQL LIKE. Este o tehnică excelentă de căutare pentru potrivirea șirului de caractere cu modelele specificate sau în cazul în care nu suntem destul de siguri de ceea ce căutați aka fuzzy search. Caracterele wildcard disponibile fac ca operatorul să fie mai flexibil. Sper că ți-a plăcut acest articol pe SQL ca operator în SQL Server. Simțiți-vă liber pune orice întrebări în comentariile de mai jos.
- autor
- Postări recente

specialitatea mea constă în proiectarea& implementarea soluțiilor de înaltă disponibilitate și migrarea DB pe mai multe platforme. Tehnologiile care lucrează în prezent sunt SQL Server, PowerShell, Oracle și MongoDB.
Vizualizați toate postările lui Prashanth Jayaram
- o prezentare rapidă a auditului bazei de date în SQL – 28 Ianuarie 2021
- cum se setează up Azure Data Sync între bazele de date Azure SQL și SQL Server local-20 ianuarie 2021
- cum se efectuează operațiuni de import/export de baze de date Azure SQL folosind PowerShell – 14 ianuarie 2021