toți utilizatorii bazei de date știu despre funcțiile agregate regulate care funcționează pe un tabel întreg și sunt utilizate cu o clauză GROUP BY. Dar foarte puțini oameni folosesc funcții de ferestre în SQL. Acestea funcționează pe un set de rânduri și returnează o singură valoare agregată pentru fiecare rând.
principalul avantaj al utilizării funcțiilor Window față de funcțiile agregate regulate este: Funcțiile ferestrei nu fac ca rândurile să fie grupate într-un singur rând de ieșire, rândurile își păstrează identitățile separate și o valoare agregată va fi adăugată fiecărui rând.
Să aruncăm o privire la modul în care funcționează funcțiile ferestrei și apoi să vedem câteva exemple de utilizare a acesteia în practică pentru a fi siguri că lucrurile sunt clare și, de asemenea, modul în care SQL și output se compară cu cele pentru funcțiile SUM ().
ca întotdeauna asigurați-vă că sunt pe deplin susținute, mai ales dacă încercați lucruri noi cu baza de date.
Introducere în funcțiile ferestrei
funcțiile ferestrei funcționează pe un set de rânduri și returnează o singură valoare agregată pentru fiecare rând. Fereastra de termen descrie setul de rânduri din Baza de date pe care va funcționa funcția.
definim fereastra (set de rânduri pe care funcționează funcțiile) folosind o clauză OVER (). Vom discuta mai multe despre clauza OVER() din articolul de mai jos.
Types of Window functions
Syntax
|
1
2
3
4
|
window_function ( expression )
OVER ( )
|
Arguments
window_function
Specify the name of the window function
ALL
ALL is an optional keyword. Când va include toate va conta toate valorile, inclusiv cele duplicat. DISTINCT nu este acceptat în funcțiile ferestrei
expression
coloana țintă sau expresia pe care funcționează funcțiile. Cu alte cuvinte, numele coloanei pentru care avem nevoie de o valoare agregată. De exemplu, o coloană care conține suma comenzii, astfel încât să putem vedea comenzile totale primite.
OVER
specifică clauzele ferestrei pentru funcțiile agregate.
PARTITION BY partition_list
definește fereastra (set de rânduri pe care funcționează funcția window) pentru funcțiile window. Trebuie să furnizăm un câmp sau o listă de câmpuri pentru partiția după partiția după clauză. Câmpurile Multiple trebuie separate printr-o virgulă ca de obicei. Dacă partiția după nu este specificată, gruparea se va face pe întregul tabel și valorile vor fi agregate în consecință.
ORDER BY order_list
sortează rândurile din fiecare partiție. Dacă comanda BY nu este specificată, comanda BY folosește întregul tabel.
Exemple
să creăm tabel și să inserăm înregistrări fictive pentru a scrie interogări suplimentare. Rulați codul de mai jos.
funcții agregate fereastră
SUM ()
știm cu toții SUM() funcția agregată. Face suma câmpului specificat pentru grupul specificat (cum ar fi orașul, statul, țara etc.) sau pentru întregul tabel dacă grupul nu este specificat. Vom vedea care va fi rezultatul funcției regulate SUM() aggregate și window SUM() aggregate.
Următorul este un exemplu de sumă regulată() funcție agregată. Acesta însumează suma comenzii pentru fiecare oraș.
puteți vedea din setul de rezultate că o funcție agregată regulată grupează mai multe rânduri într-un singur rând de ieșire, ceea ce face ca rândurile individuale să-și piardă identitatea.
|
1
2
3
4
|
selectați orașul, suma(order_amount) total_order_amount
din . Grup după oraș
|

Acest lucru nu se întâmplă cu funcțiile agregate de ferestre. Rândurile își păstrează identitatea și arată, de asemenea, o valoare agregată pentru fiecare rând. În exemplul de mai jos, interogarea face același lucru, și anume agregă datele pentru fiecare oraș și arată suma sumei totale a comenzii pentru fiecare dintre ele. Cu toate acestea, interogarea introduce acum o altă coloană pentru suma totală a comenzii, astfel încât fiecare rând să își păstreze identitatea. Coloana marcată grand_total este noua coloană din exemplul de mai jos.
AVG ()
AVG sau Average funcționează exact în același mod cu o funcție de fereastră.
următoarea interogare vă va oferi suma medie a comenzii pentru fiecare oraș și pentru fiecare lună (deși pentru simplitate am folosit date doar într-o lună).
specificăm mai multe medii specificând mai multe câmpuri din lista de partiții.
de asemenea, este demn de remarcat faptul că puteți utiliza expresii în liste, cum ar fi luna(order_date) așa cum se arată în interogarea de mai jos. Ca întotdeauna puteți face aceste expresii la fel de complexe, după cum doriți, atâta timp cât sintaxa este corectă!
Din imaginea de mai sus, putem vedea clar că, în medie, am primit comenzi de 12.333 pentru Arlington city pentru aprilie 2017.
valoarea medie a Comenzii = valoarea totală a Comenzii / totalul comenzilor
= (20,000 + 15,000 + 2,000) / 3
= 12,333
puteți utiliza, de asemenea, combinația de SUM ()& COUNT() funcție pentru a calcula o medie.
MIN ()
funcția agregată MIN() va găsi valoarea minimă pentru un grup specificat sau pentru întregul tabel dacă grupul nu este specificat.
de exemplu, căutăm cea mai mică comandă (comandă minimă) pentru fiecare oraș pe care l-am folosi următoarea interogare.
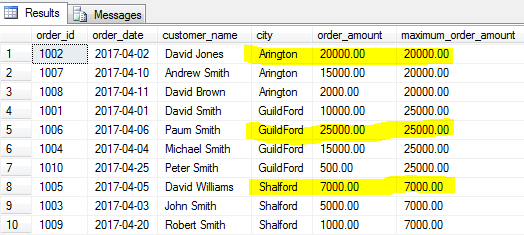
MAX ()
la fel cum funcțiile MIN() vă oferă valoarea minimă, funcția MAX() va identifica cea mai mare valoare a unui câmp specificat pentru un grup specificat de rânduri sau pentru întregul tabel dacă un grup nu este specificat.
să găsim cea mai mare comandă (suma maximă a comenzii) pentru fiecare oraș.
COUNT ()
funcția COUNT() va număra înregistrările / rândurile.
rețineți că DISTINCT nu este acceptat cu funcția window COUNT (), în timp ce este acceptat pentru funcția regular COUNT (). DISTINCT vă ajută să găsiți valorile distincte ale unui câmp specificat.
de exemplu, dacă dorim să vedem câți clienți au plasat o comandă în aprilie 2017, nu putem număra direct toți clienții. Este posibil ca același client să fi plasat mai multe comenzi în aceeași lună.
COUNT(customer_name) vă va da un rezultat incorect, deoarece va conta duplicate. Întrucât COUNT (DISTINCT customer_name) vă va oferi rezultatul corect, deoarece contează fiecare client unic o singură dată.
valabil pentru numărarea regulată () funcție:
|
1
2
3
4
5
|
selectați orașul,numărul(distinct customer_name) number_of_customers
din .
grup după oraș
|
Invalid pentru numărul de ferestre() funcție:
interogarea de mai sus cu funcția de fereastră vă va da mai jos eroare.
acum, să găsim comanda totală primită pentru fiecare oraș folosind funcția window COUNT ().
funcții de clasare a ferestrelor
la fel cum funcțiile agregate ale ferestrelor agregă valoarea unui câmp specificat, funcțiile de clasare vor clasifica valorile unui câmp specificat și le vor clasifica în funcție de rangul lor.
cea mai obișnuită utilizare a funcțiilor de clasare este de a găsi înregistrările de top (N) pe baza unei anumite valori. De exemplu, Top 10 angajați cel mai bine plătiți, top 10 studenți clasați, Top 50 cele mai mari comenzi etc.
sunt acceptate următoarele funcții de clasare:
RANK(), DENSE_RANK(), ROW_NUMBER(), NTILE ()
să le discutăm unul câte unul.
RANK ()
funcția RANK() este utilizată pentru a da un rang unic fiecărei înregistrări pe baza unei valori specificate, de exemplu salariu, suma comenzii etc.
dacă două înregistrări au aceeași valoare, atunci funcția RANK() va atribui același rang ambelor înregistrări sărind peste următorul rang. Aceasta înseamnă – dacă există două valori identice la rangul 2, Acesta va atribui același rang 2 ambelor înregistrări și apoi va sări peste rangul 3 și va atribui rangul 4 următoarei înregistrări.
să clasificăm fiecare comandă după valoarea comenzii.
|
1
2
3
4
5
|
selectați order_id,order_date,customer_name,oraș,
rank() over(order by order_amount desc)
din .
|
Din imaginea de mai sus, puteți vedea că același rang (3) este atribuit la două înregistrări identice (fiecare având o sumă de comandă de 15.000) și apoi omite următorul rang (4) și atribuie rangul 5 la următoarea înregistrare.
DENSE_RANK ()
funcția DENSE_RANK() este identică cu funcția RANK (), cu excepția faptului că nu omite Niciun rang. Aceasta înseamnă că, dacă se găsesc două înregistrări identice, atunci DENSE_RANK() va atribui același rang ambelor înregistrări, dar nu va sări, apoi va sări peste următorul rang.
Să vedem cum funcționează în practică.
după cum puteți vedea clar mai sus, același rang este dat la două înregistrări identice (fiecare având aceeași sumă de ordine) și apoi următorul număr de rang este dat la următoarea înregistrare fără a sări peste o valoare de rang.
ROW_NUMBER ()
numele este auto-explicativ. Aceste funcții atribuie un număr de rând unic fiecărei înregistrări.
Numărul rândului va fi resetat pentru fiecare partiție dacă este specificată partiția BY. Să vedem cum ROW_NUMBER () funcționează fără partiție de și apoi cu partiție de.
ROW_ NUMBER() fără partiție de
ROW_NUMBER() cu partiție de
rețineți că am făcut partiția pe oraș. Aceasta înseamnă că numărul rândului este resetat pentru fiecare oraș și astfel repornește din nou la 1. Cu toate acestea, ordinea rândurilor este determinată de suma comenzii, astfel încât pentru orice oraș dat cea mai mare sumă de comandă va fi primul rând și astfel atribuit numărul rândului 1.
NTILE ()
NTILE() este o funcție de fereastră foarte utilă. Vă ajută să identificați în ce percentilă (sau quartilă sau orice altă subdiviziune) se încadrează un rând dat.
aceasta înseamnă că dacă aveți 100 de rânduri și doriți să creați 4 quartile pe baza unui câmp de valoare specificat, puteți face acest lucru cu ușurință și puteți vedea câte rânduri se încadrează în fiecare quartilă.
să vedem un exemplu. În interogarea de mai jos, am specificat că dorim să creăm patru quartile pe baza sumei comenzii. Apoi vrem să vedem câte ordine cad în fiecare quartilă.
NTILE creează plăci pe baza următoarei formule:
nr de rânduri în fiecare țiglă = numărul de rânduri din setul de rezultate/numărul de plăci specificate
Iată exemplul nostru, avem în total 10 rânduri și 4 plăci sunt specificate în interogare, astfel încât numărul de rânduri din fiecare țiglă va fi de 2,5 (10/4). Ca număr de rânduri ar trebui să fie număr întreg, nu o zecimală. SQL engine va atribui 3 rânduri pentru primele două grupuri și 2 rânduri pentru celelalte două grupuri.
funcții fereastră valoare
LAG() și plumb ()
plumb() și LAG() funcții sunt foarte puternice, dar pot fi complexe pentru a explica.
deoarece acesta este un articol introductiv de mai jos, ne uităm la un exemplu foarte simplu pentru a ilustra modul de utilizare a acestora.
funcția LAG permite accesarea datelor din rândul anterior din același set de rezultate fără utilizarea niciunei îmbinări SQL. Puteti vedea in exemplul de mai jos, folosind funcția LAG am găsit data comenzii anterioare.
Script pentru a găsi data comenzii anterioare folosind funcția LAG ():
funcția LEAD permite accesarea datelor din rândul următor din același set de rezultate fără utilizarea niciunei îmbinări SQL. Puteti vedea in exemplul de mai jos, folosind funcția de plumb am găsit data următoare comandă.
Script pentru a găsi următoarea dată de comandă folosind funcția LEAD ():
FIRST_VALUE () și LAST_VALUE ()
aceste funcții vă ajută să identificați prima și ultima înregistrare dintr-o partiție sau dintr-un tabel întreg dacă partiția după nu este specificată.
să găsim prima și ultima comandă a fiecărui oraș din setul nostru de date existent. Notă comanda prin clauza este obligatorie pentru FIRST_VALUE () și last_value () funcții
Din imaginea de mai sus, putem vedea în mod clar că prima comandă primită pe 2017-04-02 și ultima comandă primită pe 2017-04-11 pentru Arlington city și funcționează la fel pentru alte orașe.
link-uri utile
- tipuri de Backup& strategii pentru baze de date SQL
- TechNet articol pe Clauza de peste
- MSDN articol pe DENSE_RANK
alte articole mari de la Ben
cum SQL Server Selectează o victimă impas
Cum pentru a utiliza funcțiile ferestrei
- autor
- postări recente
Vizualizați toate postările lui Ben Richardson
- Power BI: diagrame de cascadă și imagini combinate – 19 ianuarie 2021
- putere BI: Formatare condiționată și culori de date în acțiune-14 Ianuarie 2021
- Power BI: importul datelor din SQL Server și MySQL – 12 ianuarie 2021