
Klassifizierungstechniken sind ein wesentlicher Bestandteil von Machine Learning- und Data Mining-Anwendungen. Ungefähr 70% der Probleme in der Datenwissenschaft sind Klassifizierungsprobleme. Es gibt viele Klassifizierungsprobleme, die verfügbar sind, aber die binäre Regression ist üblich und eine nützliche Regressionsmethode zur Lösung des binären Klassifizierungsproblems. Eine andere Klassifizierungskategorie ist die Multinomialklassifikation, die die Probleme behandelt, bei denen mehrere Klassen in der Zielvariablen vorhanden sind. Zum Beispiel ist IRIS ein sehr berühmtes Beispiel für die Klassifizierung mehrerer Klassen. Andere Beispiele sind die Klassifizierung der Kategorie Artikel / Blog / Dokument.
Die logistische Regression kann für verschiedene Klassifizierungsprobleme wie die Spam-Erkennung verwendet werden. Diabetes-Vorhersage, ob ein bestimmter Kunde ein bestimmtes Produkt kauft oder einen anderen Konkurrenten abwandert, ob der Benutzer auf einen bestimmten Werbelink klickt oder nicht, und viele weitere Beispiele sind in der Liste.
Die logistische Regression ist einer der einfachsten und am häufigsten verwendeten maschinellen Lernalgorithmen für die Zwei-Klassen-Klassifikation. Es ist einfach zu implementieren und kann als Basis für jedes binäre Klassifizierungsproblem verwendet werden. Seine grundlegenden Grundkonzepte sind auch im Deep Learning konstruktiv. Die logistische Regression beschreibt und schätzt die Beziehung zwischen einer abhängigen binären Variablen und unabhängigen Variablen.
In diesem Tutorial lernen Sie die folgenden Dinge in der logistischen Regression:
- Einführung in die logistische Regression
- Lineare Regression Vs. Logistische Regression
- Maximum-Likelihood-Schätzung Vs. Gewöhnliche Methode des kleinsten Quadrats
- Wie funktioniert die logistische Regression?
- Modellbau in Scikit-learn
- Modellauswertung mit Verwirrungsmatrix.
- Vor- und Nachteile der logistischen Regression
Logistische Regression
Die logistische Regression ist eine statistische Methode zur Vorhersage binärer Klassen. Das Ergebnis oder die Zielvariable ist dichotomer Natur. Dichotom bedeutet, dass es nur zwei mögliche Klassen gibt. Zum Beispiel kann es für Krebserkennungsprobleme verwendet werden. Es berechnet die Wahrscheinlichkeit eines Ereigniseintritts.
Es ist ein Sonderfall der linearen Regression, bei dem die Zielvariable kategorischer Natur ist. Es verwendet ein Protokoll der Quoten als abhängige Variable. Logistic Regression predicts the probability of occurrence of a binary event utilizing a logit function.
Linear Regression Equation:
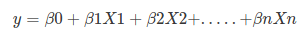
Where, y is dependent variable and x1, x2 … and Xn are explanatory variables.
Sigmoid Function:
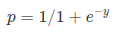
Apply Sigmoid function on linear regression:
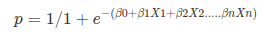
Properties of Logistic Regression:
- Die abhängige Variable in der logistischen Regression folgt der Bernoulli-Verteilung.
- Die Schätzung erfolgt durch maximale Wahrscheinlichkeit.
- Kein R-Quadrat, Modell Fitness wird durch Konkordanz berechnet, KS-Statistik.
Lineare Regression Vs. Logistische Regression
Die lineare Regression liefert eine kontinuierliche Ausgabe, die logistische Regression jedoch eine konstante Ausgabe. Ein Beispiel für die kontinuierliche Ausgabe ist der Hauspreis und der Aktienkurs. Ein Beispiel für die diskrete Ausgabe ist die Vorhersage, ob ein Patient Krebs hat oder nicht, und die Vorhersage, ob der Kunde abwandern wird. Die lineare Regression wird mit gewöhnlichen kleinsten Quadraten (OLS) geschätzt, während die logistische Regression mit dem Maximum-Likelihood-Estimation-Ansatz (MLE) geschätzt wird.

Maximum-Likelihood-Schätzung vs. Least-Square-Methode
Die MLE ist eine „Likelihood“ -Maximierungsmethode, während OLS eine entfernungsminimierende Näherungsmethode ist. Die Maximierung der Likelihood-Funktion bestimmt die Parameter, die die beobachteten Daten am wahrscheinlichsten erzeugen. Aus statistischer Sicht legt MLE den Mittelwert und die Varianz als Parameter fest, um die spezifischen Parameterwerte für ein bestimmtes Modell zu bestimmen. Dieser Parametersatz kann zur Vorhersage der Daten verwendet werden, die in einer Normalverteilung benötigt werden.
Gewöhnliche Schätzungen der kleinsten Quadrate werden berechnet, indem eine Regressionsgerade an gegebene Datenpunkte angepasst wird, die die minimale Summe der quadratischen Abweichungen (kleinster quadratischer Fehler) aufweist. Beide werden verwendet, um die Parameter eines linearen Regressionsmodells zu schätzen. MLE geht von einer gemeinsamen Wahrscheinlichkeitsmassefunktion aus, während OLS keine stochastischen Annahmen zur Minimierung der Entfernung erfordert.
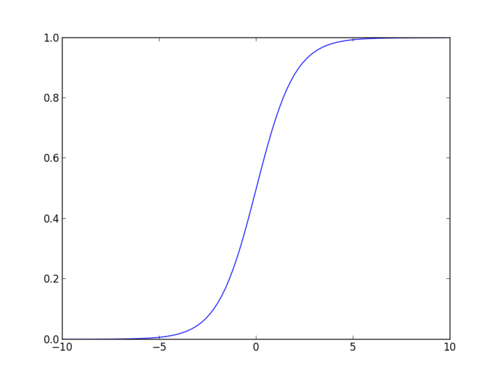
Sigmoidfunktion
Die Sigmoidfunktion, auch logistische Funktion genannt, ergibt eine S-förmige Kurve, die jede reelle Zahl in einen Wert zwischen 0 und 1 abbilden kann. Wenn die Kurve in die positive Unendlichkeit geht, wird y vorhergesagt zu 1, und wenn die Kurve in die negative Unendlichkeit geht, wird y vorhergesagt zu 0. Wenn die Ausgabe der Sigmoidfunktion mehr als 0,5 beträgt, können wir das Ergebnis als 1 oder JA klassifizieren und wenn es kleiner als 0 ist.5, können wir es als 0 oder NEIN klassifizieren. Die outputcannotFor Beispiel: Wenn die Ausgabe 0,75 ist, können wir in Bezug auf die Wahrscheinlichkeit sagen, wie: Es gibt eine 75-prozentige Chance, dass der Patient an Krebs leiden.
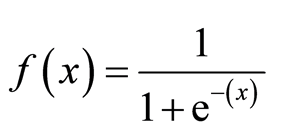
Arten der logistischen Regression
Arten der logistischen Regression:
- Binäre logistische Regression: Die Zielvariable hat nur zwei mögliche Ergebnisse wie Spam oder kein Spam, Krebs oder Kein Krebs.
- Multinomiale logistische Regression: Die Zielvariable hat drei oder mehr nominale Kategorien, z. B. die Vorhersage der Weinsorte.
- Ordinale logistische Regression: Die Zielvariable hat drei oder mehr ordinale Kategorien wie Restaurant oder Produktbewertung von 1 bis 5.
Modellbildung in Scikit-learn
Lassen Sie uns das Diabetes-Vorhersagemodell erstellen.
Hier werden Sie Diabetes mit dem Logistischen Regressionsklassifikator vorhersagen.
Laden wir zuerst den erforderlichen Pima Indian Diabetes-Datensatz mit der read CSV-Funktion von Pandas. Sie können Daten von folgendem Link herunterladen: https://www.kaggle.com/uciml/pima-indians-diabetes-database
Laden von Daten
#import pandasimport pandas as pdcol_names = # load datasetpima = pd.read_csv("pima-indians-diabetes.csv", header=None, names=col_names)pima.head()
Feature auswählen
Hier müssen Sie die angegebenen Spalten in zwei Arten von Variablen unterteilen abhängige(oder Zielvariable) und unabhängige Variable(oder Merkmalsvariable).
#split dataset in features and target variablefeature_cols = X = pima # Featuresy = pima.label # Target variableDaten aufteilen
Um die Modellleistung zu verstehen, ist die Aufteilung des Datensatzes in einen Trainingssatz und einen Testsatz eine gute Strategie.
Teilen wir den Datensatz mit der Funktion train_test_split() . Sie müssen 3 Parameter features , target und test_set size übergeben. Darüber hinaus können Sie random_state verwenden, um Datensätze zufällig auszuwählen.
# split X and y into training and testing setsfrom sklearn.cross_validation import train_test_splitX_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=0)/home/admin/.local/lib/python3.5/site-packages/sklearn/cross_validation.py:41: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also, note that the interface of the new CV iterators is different from that of this module. This module will be removed in 0.20. "This module will be removed in 0.20.", DeprecationWarning)Hier ist der Datensatz im Verhältnis 75:25 in zwei Teile zerlegt. Dies bedeutet, dass 75% der Daten für das Modelltraining und 25% für Modelltests verwendet werden.
Modellentwicklung und Vorhersage
Importieren Sie zunächst das Logistische Regressionsmodul und erstellen Sie ein Logistisches Regressionsklassifikatorobjekt mit der Funktion LogisticRegression().
Passen Sie dann Ihr Modell mit fit() an den Zugsatz an und führen Sie mit predict() eine Vorhersage für den Testsatz durch.
# import the classfrom sklearn.linear_model import LogisticRegression# instantiate the model (using the default parameters)logreg = LogisticRegression()# fit the model with datalogreg.fit(X_train,y_train)#y_pred=logreg.predict(X_test)Modellbewertung mit Konfusionsmatrix
Eine Konfusionsmatrix ist eine Tabelle, die zur Bewertung der Leistung eines Klassifikationsmodells verwendet wird. Sie können auch die Leistung eines Algorithmus visualisieren. Die Grundlage einer Konfusionsmatrix ist die Anzahl der richtigen und falschen Vorhersagen, die klassenweise zusammengefasst werden.
# import the metrics classfrom sklearn import metricscnf_matrix = metrics.confusion_matrix(y_test, y_pred)cnf_matrixarray(, ])Hier sehen Sie die Verwirrungsmatrix in Form des Array-Objekts. Die Dimension dieser Matrix ist 2 * 2, da dieses Modell eine binäre Klassifizierung ist. Sie haben zwei Klassen 0 und 1. Diagonalwerte stellen genaue Vorhersagen dar, während nicht diagonale Elemente ungenaue Vorhersagen sind. In der Ausgabe sind 119 und 36 tatsächliche Vorhersagen und 26 und 11 falsche Vorhersagen.
Konfusionsmatrix mit Heatmap visualisieren
Lassen Sie uns die Ergebnisse des Modells in Form einer Konfusionsmatrix mit matplotlib und seaborn visualisieren.
Hier visualisieren Sie die Verwirrungsmatrix mithilfe einer Heatmap.
# import required modulesimport numpy as npimport matplotlib.pyplot as pltimport seaborn as sns%matplotlib inlineclass_names= # name of classesfig, ax = plt.subplots()tick_marks = np.arange(len(class_names))plt.xticks(tick_marks, class_names)plt.yticks(tick_marks, class_names)# create heatmapsns.heatmap(pd.DataFrame(cnf_matrix), annot=True, cmap="YlGnBu" ,fmt='g')ax.xaxis.set_label_position("top")plt.tight_layout()plt.title('Confusion matrix', y=1.1)plt.ylabel('Actual label')plt.xlabel('Predicted label')Text(0.5,257.44,'Predicted label')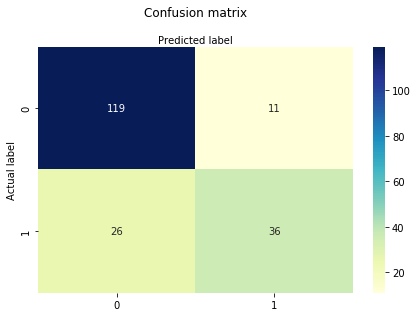
Verwirrungsmatrix-Bewertungsmetriken
Lassen Sie uns das Modell anhand von Modellbewertungsmetriken wie Genauigkeit, Präzision und Rückruf bewerten.
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))print("Precision:",metrics.precision_score(y_test, y_pred))print("Recall:",metrics.recall_score(y_test, y_pred))Accuracy: 0.8072916666666666Precision: 0.7659574468085106Recall: 0.5806451612903226Nun, Sie haben eine Klassifizierungsrate von 80%, die als gute Genauigkeit angesehen wird.
Präzision: Bei Präzision geht es darum, präzise zu sein, d. H. Wie genau Ihr Modell ist. Mit anderen Worten, Sie können sagen, wenn ein Modell eine Vorhersage macht, wie oft es richtig ist. In Ihrem Vorhersagefall, wenn Ihr Logistisches Regressionsmodell vorhergesagt hat, dass Patienten an Diabetes leiden werden, haben diese Patienten 76% der Zeit.
Rückruf: Wenn es Patienten gibt, die Diabetes im Testsatz haben und Ihr Logistisches Regressionsmodell es 58% der Zeit identifizieren kann.
ROC-Kurve
Die ROC-Kurve(Receiver Operating Characteristic) ist ein Diagramm der wahren positiven Rate gegen die falsch positive Rate. Es zeigt den Kompromiss zwischen Sensitivität und Spezifität.
y_pred_proba = logreg.predict_proba(X_test)fpr, tpr, _ = metrics.roc_curve(y_test, y_pred_proba)auc = metrics.roc_auc_score(y_test, y_pred_proba)plt.plot(fpr,tpr,label="data 1, auc="+str(auc))plt.legend(loc=4)plt.show()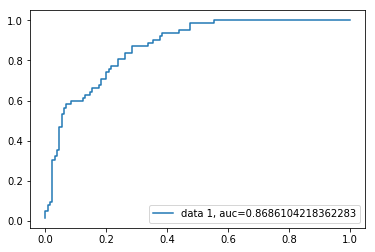
Der AUC-Wert für den Fall beträgt 0,86. Der AUC-Wert 1 steht für einen perfekten Klassifikator und 0,5 für einen wertlosen Klassifikator.
Vorteile
Aufgrund seiner effizienten und unkomplizierten Natur erfordert es keine hohe Rechenleistung, ist einfach zu implementieren, leicht interpretierbar und wird von Datenanalysten und Wissenschaftlern häufig verwendet. Außerdem ist keine Skalierung der Funktionen erforderlich. Die logistische Regression liefert einen Wahrscheinlichkeitswert für Beobachtungen.
Nachteile
Die logistische Regression kann eine große Anzahl von kategorialen Merkmalen / Variablen nicht verarbeiten. Es ist anfällig für Überanpassung. Außerdem kann das nichtlineare Problem mit der logistischen Regression nicht gelöst werden, weshalb eine Transformation nichtlinearer Merkmale erforderlich ist. Die logistische Regression funktioniert nicht gut mit unabhängigen Variablen, die nicht mit der Zielvariablen korrelieren und sehr ähnlich oder korreliert sind.
Fazit
In diesem Tutorial haben Sie viele Details zur Logistischen Regression behandelt. Sie haben gelernt, was die logistische Regression ist, wie man entsprechende Modelle erstellt, wie man Ergebnisse visualisiert und einige der theoretischen Hintergrundinformationen. Außerdem haben Sie einige grundlegende Konzepte wie die Sigmoidfunktion, die maximale Wahrscheinlichkeit, die Verwirrungsmatrix und die ROC-Kurve behandelt.
Hoffentlich können Sie jetzt die Logistische Regressionstechnik verwenden, um Ihre eigenen Datensätze zu analysieren. Vielen Dank für das Lesen dieses Tutorials!
Wenn Sie mehr über Logistische Regression erfahren möchten, besuchen Sie den Kurs Grundlagen der prädiktiven Analytik in Python (Teil 1) von DataCamp.