
En este tutorial, vamos a aprender de Regresión Logística. Aquí sabrás exactamente qué es Regresión Logística y también verás un ejemplo con Python. La regresión logística es un tema importante del Aprendizaje automático y trataré de hacerlo lo más simple posible.
A principios del siglo XX, la regresión logística se utilizó principalmente en Biología, después de esto, se usó en algunas aplicaciones de ciencias sociales. Si tiene curiosidad, puede preguntar dónde debemos usar la regresión logística. Así que usamos Regresión logística cuando nuestra variable independiente es categórica.
Ejemplos:
- Para predecir si una persona comprará un automóvil (1) o (0)
- Para saber si el tumor es maligno (1) o (0)
Ahora consideremos un escenario en el que debe clasificar si una persona comprará un automóvil o no. En este caso, si usamos regresión lineal simple, necesitaremos especificar un umbral sobre el que se puede hacer la clasificación.
Digamos que la clase real es la persona que comprará el automóvil, y el valor continuo predicho es 0.45 y el umbral que hemos considerado es 0.5, entonces este punto de datos se considerará que la persona no comprará el automóvil y esto conducirá a la predicción incorrecta.
Así que concluimos que no podemos usar regresión lineal para este tipo de problema de clasificación. Como sabemos, la regresión lineal está limitada, por lo que aquí viene la regresión logística donde el valor varía estrictamente de 0 a 1.
Regresión Logística Simple:
Salida: 0 o 1
Hipótesis: K = W * X + B
hΘ(x) = sigmoide(K)
Función Sigmoide:


Tipos de Regresión Logística:
Regresión Logística Binaria
Sólo dos resultados posibles(Categoría).Ejemplo: La persona comprará un auto o no.
Regresión Logística Multinomial
Más de dos Categorías posibles sin ordenar.
Regresión Logística Ordinal
Más de dos categorías posibles con el pedido.
Ejemplo del mundo real con Python:
Ahora resolveremos un problema del mundo real con Regresión Logística. Tenemos un conjunto de datos que tiene 5 columnas, a saber: ID de usuario, Sexo, Edad, Estimado y Comprado. Ahora tenemos que construir un modelo que pueda predecir si en el parámetro dado una persona comprará un automóvil o no.
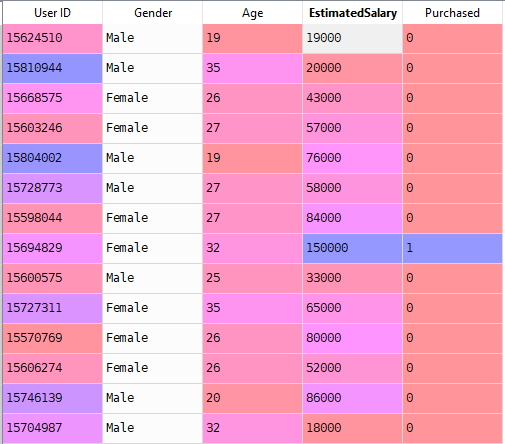
Pasos Para Construir el Modelo:
1. Importing the libraries
Aquí importaremos las bibliotecas que se necesitarán para construir el modelo.
import numpy as npimport matplotlib.pyplot as pltimport pandas as pd2. Importing the Data set
Importaremos nuestro conjunto de datos en una variable (es decir, conjunto de datos) utilizando pandas.
dataset = pd.read_csv('Social_Network_Ads.csv')3. Splitting our Data set in Dependent and Independent variables.
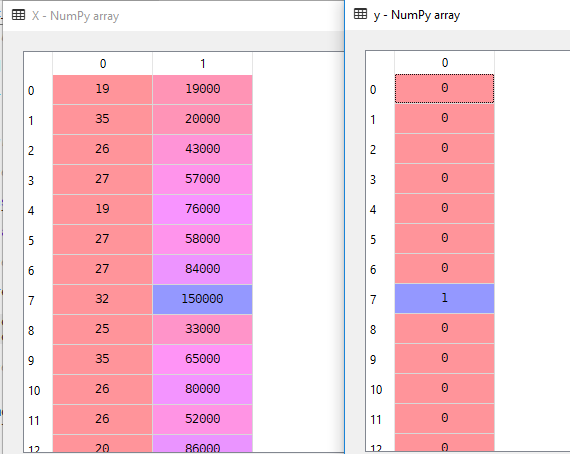
En nuestro conjunto de Datos vamos a considerar la Edad y EstimatedSalary como variable Independiente y Comprado como Variable Dependiente.
X = dataset.iloc].valuesy = dataset.iloc.valuesAquí X es variable independiente e y es Variable dependiente.
3. Splitting the Data set into the Training Set and Test Set
Ahora vamos a dividir nuestro conjunto de Datos en los Datos de Entrenamiento y Datos de Prueba. Los datos de entrenamiento se utilizarán para entrenar nuestro modelo logístico y los datos de prueba se utilizarán para validar nuestro modelo. Usaremos Sklearn para dividir nuestros datos. Vamos a importar train_test_split de sklearn.model_selection
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
4. Feature Scaling
Ahora vamos a hacer la función de escalado de la escala de nuestros datos entre 0 y 1 para obtener una mejor precisión.
Aquí el escalado es importante porque hay una gran diferencia entre la edad y la estimación.
- Importar StandardScaler desde sklearn.preprocesamiento
- a Continuación, hacer una instancia sc_X del objeto StandardScaler
- a Continuación, ajuste y transformar X_train y transformar X_test
from sklearn.preprocessing import StandardScalersc_X = StandardScaler()X_train = sc_X.fit_transform(X_train)X_test = sc_X.transform(X_test)
5. Fitting Logistic Regression to the Training Set
Ahora vamos a construir nuestro clasificador (Logística).
- Importar LogisticRegression desde sklearn.linear_model
- Haga un clasificador de instancia del objeto LogisticRegression y dé
random_state = 0 para obtener el mismo resultado cada vez. - Ahora use este clasificador para ajustar X_train y y_train
from sklearn.linear_model import LogisticRegressionclassifier = LogisticRegression(random_state=0)classifier.fit(X_train, y_train)¡Salud!! Después de ejecutar el comando anterior, tendrá un clasificador que puede predecir si una persona comprará un automóvil o no.
Ahora use el clasificador para hacer la predicción para el conjunto de datos de prueba y encuentre la precisión utilizando la matriz de confusión.
6. Predicting the Test set results
y_pred = classifier.predict(X_test)Ahora vamos a obtener y_pred

Ahora podemos utilizar y_test (Resultado Real) y y_pred ( Resultado previsto) para obtener la exactitud de nuestro modelo.
7. Making the Confusion Matrix
Usando la matriz de confusión podemos obtener precisión de nuestro modelo.
from sklearn.metrics import confusion_matrixcm = confusion_matrix(y_test, y_pred)Obtendrá una matriz cm .

el Uso de cm para calcular la precisión como se muestra a continuación:
Exactitud = ( cm + cm ) / ( Total de la prueba de puntos de datos )

Aquí vemos la precisión del 89 % . ¡Salud!! estamos obteniendo una buena precisión.
Finalmente, visualizaremos el resultado de nuestro conjunto de entrenamiento y el resultado del conjunto de pruebas. Usaremos matplotlib para trazar nuestro conjunto de datos.
Visualizar el Conjunto de Entrenamiento resultado
from matplotlib.colors import ListedColormapX_set, y_set = X_train, y_trainX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Training set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()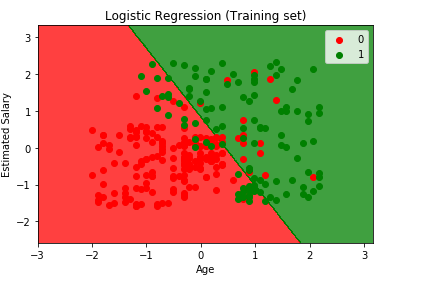
Visualización de la Prueba de Conjunto el resultado es
from matplotlib.colors import ListedColormapX_set, y_set = X_test, y_testX1, X2 = np.meshgrid(np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01), np.arange(start = X_set.min() - 1, stop = X_set.max() + 1, step = 0.01))plt.contourf(X1, X2, classifier.predict(np.array().T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green')))plt.xlim(X1.min(), X1.max())plt.ylim(X2.min(), X2.max())for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set, X_set, c = ListedColormap(('red', 'green'))(i), label = j)plt.title('Logistic Regression (Test set)')plt.xlabel('Age')plt.ylabel('Estimated Salary')plt.legend()plt.show()
Ahora Usted puede construir su propio clasificador para la Regresión Logística.
Gracias!! ¡Sigue Programando !!
Nota: Esta es una publicación invitada, y la opinión en este artículo es del escritor invitado. Si tiene algún problema con alguno de los artículos publicados en www.marktechpost.com please contact at [email protected]
Advertisement
