Reconocimiento facial: Paso a paso
Abordemos este problema paso a paso. Para cada paso, aprenderemos sobre un algoritmo de aprendizaje automático diferente. No voy a explicar cada algoritmo por completo para evitar que esto se convierta en un libro, pero aprenderás las ideas principales detrás de cada uno y aprenderás cómo puedes construir tu propio sistema de reconocimiento facial en Python usando OpenFace y dlib.
Paso 1: Encontrar todas las caras
El primer paso de nuestra canalización es la detección de caras. Obviamente, necesitamos localizar las caras en una fotografía antes de que podamos tratar de distinguirlas.
Si usted ha utilizado una cámara en los últimos 10 años, usted probablemente ha visto la detección de la cara en acción:

detección de la Cara es una gran característica para las cámaras. Cuando la cámara puede seleccionar automáticamente las caras, puede asegurarse de que todas las caras estén enfocadas antes de tomar la foto. Pero lo usaremos para un propósito diferente: encontrar las áreas de la imagen que queremos pasar al siguiente paso de nuestra canalización.
La detección de rostros se hizo popular a principios de la década de 2000, cuando Paul Viola y Michael Jones inventaron una forma de detectar rostros que era lo suficientemente rápida como para funcionar con cámaras baratas. Sin embargo, ahora existen soluciones mucho más fiables. Vamos a usar un método inventado en 2005 llamado Histograma de Gradientes Orientados, o simplemente HOG, para abreviar.
Para encontrar caras en una imagen, vamos a empezar por hacer nuestra imagen en blanco y negro porque no tenemos los datos de color a buscar caras:

a Continuación veremos cada uno de los píxeles de nuestra imagen de una en una. Para cada píxel, queremos ver los píxeles que lo rodean directamente:

Nuestro objetivo es averiguar qué oscuro el píxel actual se compara con los píxeles que lo rodean. A continuación, queremos dibujar una flecha que muestre en qué dirección se oscurece la imagen:

Si repite ese proceso para cada píxel de la imagen, terminará reemplazando cada píxel por una flecha. Estas flechas se llaman gradientes y muestran el flujo de luz a oscuridad a lo largo de toda la imagen:
Esto puede parecer aleatorio cosa que hacer, pero hay una muy buena razón para reemplazar los píxeles con los degradados. Si analizamos píxeles directamente, las imágenes realmente oscuras y las imágenes realmente claras de la misma persona tendrán valores de píxeles totalmente diferentes. Pero al considerar solo la dirección en la que cambia el brillo, tanto las imágenes realmente oscuras como las imágenes realmente brillantes terminarán con la misma representación exacta. Que hace que el problema sea mucho más fácil de resolver!
Pero guardar el degradado para cada píxel nos da demasiados detalles. Terminamos perdiendo el bosque por los árboles. Sería mejor si pudiéramos ver el flujo básico de luminosidad / oscuridad a un nivel superior para que pudiéramos ver el patrón básico de la imagen.
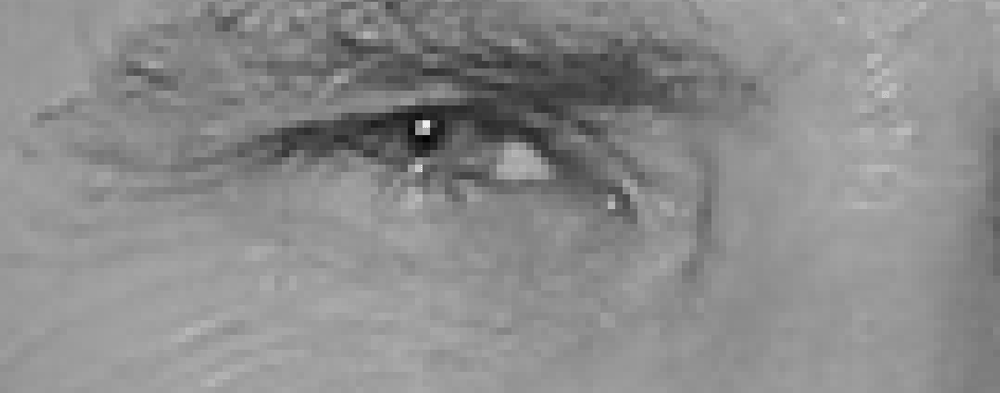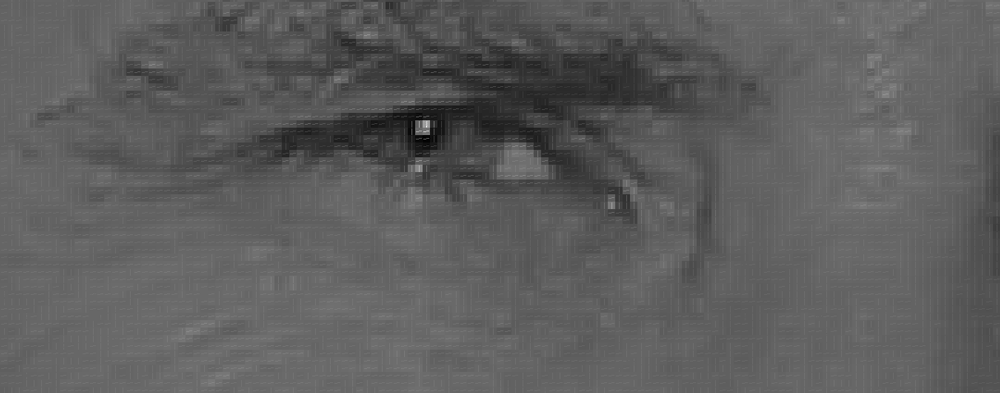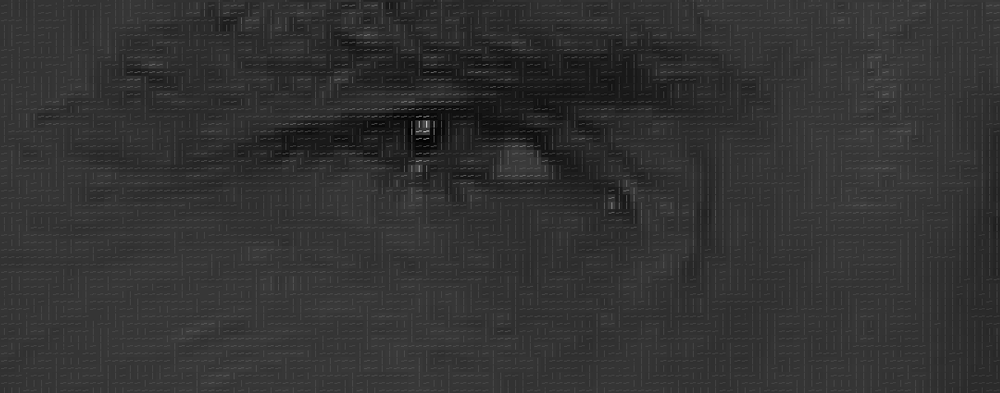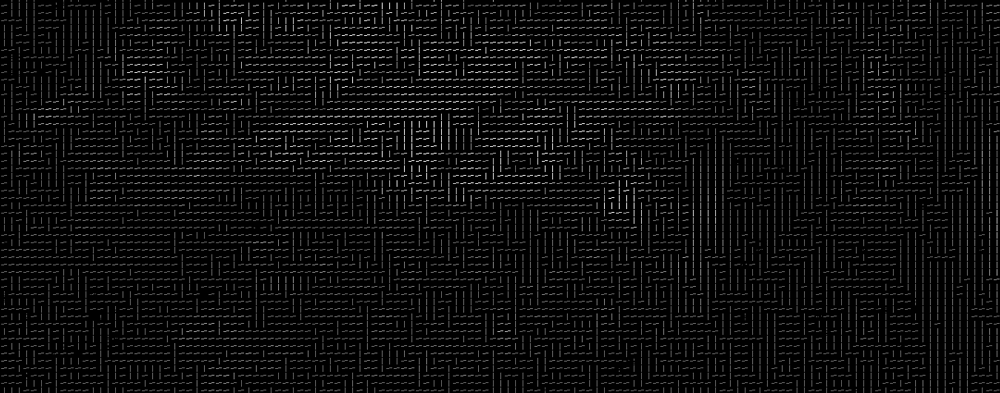
Para hacer esto, dividiremos la imagen en pequeños cuadrados de 16×16 píxeles cada uno. En cada cuadrado, contaremos cuántos degradados apuntan en cada dirección principal (cuántos puntos hacia arriba, hacia arriba, a la derecha, a la derecha, etc.). Luego reemplazaremos ese cuadrado de la imagen con las direcciones de flecha que eran las más fuertes.
El resultado final es giramos a la imagen original en una representación muy sencilla que captura la estructura básica de un rostro, de una manera sencilla:

Para encontrar caras en esta parte del CERDO de la imagen, todo lo que tenemos que hacer es encontrar la parte de la imagen que se ve muy similar a un conocido patrón de CERDO, que se extrae de un montón de otras entrenamiento caras:

el Uso de esta técnica, ahora podemos encontrar fácilmente las caras en cualquier imagen:

Si quieres probar este paso usted mismo usando Python y dlib, aquí está el código que muestra cómo generar y ver HOG representaciones de imágenes.
Paso 2: Posar y proyectar caras
Uf, aislamos las caras en nuestra imagen. Pero ahora tenemos que lidiar con el problema de que las caras giradas en diferentes direcciones se ven totalmente diferentes a una computadora:

Para tener en cuenta esto, intentaremos deformar cada imagen para que los ojos y los labios estén siempre en el lugar de muestra de la imagen. Esto hará que sea mucho más fácil para nosotros comparar caras en los próximos pasos.
Para hacer esto, vamos a usar un algoritmo llamado estimación de puntos de referencia de cara. Hay muchas maneras de hacer esto, pero vamos a usar el enfoque inventado en 2014 por Vahid Kazemi y Josephine Sullivan.
La idea básica es que encontraremos 68 puntos específicos (llamados puntos de referencia) que existen en cada cara: la parte superior de la barbilla, el borde exterior de cada ojo, el borde interior de cada ceja, etc. Luego entrenaremos un algoritmo de aprendizaje automático para poder encontrar estos 68 puntos específicos en cualquier cara:

Aquí está el resultado de la localización de la 68 cara hitos en nuestra imagen de prueba:

Ahora que sabemos dónde están los ojos y la boca, simplemente giraremos, escalaremos y cortaremos la imagen para que los ojos y la boca estén lo mejor centrados posible. No haremos deformaciones 3D de lujo porque eso introduciría distorsiones en la imagen. Solo vamos a usar transformaciones de imagen básicas como rotación y escala que preservan líneas paralelas (llamadas transformaciones afines):

Ahora no importa cómo la cara se de vuelta, somos capaces de centro de los ojos y la boca están aproximadamente en la misma posición en la imagen. Esto hará que nuestro siguiente paso sea mucho más preciso.
Si quieres probar este paso tú mismo usando Python y dlib, aquí está el código para encontrar puntos de referencia de cara y aquí está el código para transformar la imagen usando esos puntos de referencia.
Paso 3: Codificar caras
Ahora estamos en la carne del problema: distinguir caras. ¡Aquí es donde las cosas se ponen realmente interesantes!
El enfoque más simple para el reconocimiento facial es comparar directamente la cara desconocida que encontramos en el Paso 2 con todas las imágenes que tenemos de personas que ya han sido etiquetadas. Cuando encontramos una cara previamente etiquetada que se parece mucho a nuestra cara desconocida, debe ser la misma persona. Parece una buena idea, ¿verdad?
En realidad hay un gran problema con ese enfoque. Un sitio como Facebook con miles de millones de usuarios y un billón de fotos no puede recorrer todas las caras etiquetadas previamente para compararlas con cada imagen recién subida. Eso llevaría demasiado tiempo. Necesitan ser capaces de reconocer caras en milisegundos, no en horas.
Lo que necesitamos es una forma de extraer algunas medidas básicas de cada cara. Entonces podríamos medir nuestra cara desconocida de la misma manera y encontrar la cara conocida con las medidas más cercanas. Por ejemplo, podemos medir el tamaño de cada oreja, el espacio entre los ojos, la longitud de la nariz, etc. Si alguna vez has visto un mal crimen mostrar como CSI, usted sabe de qué estoy hablando:
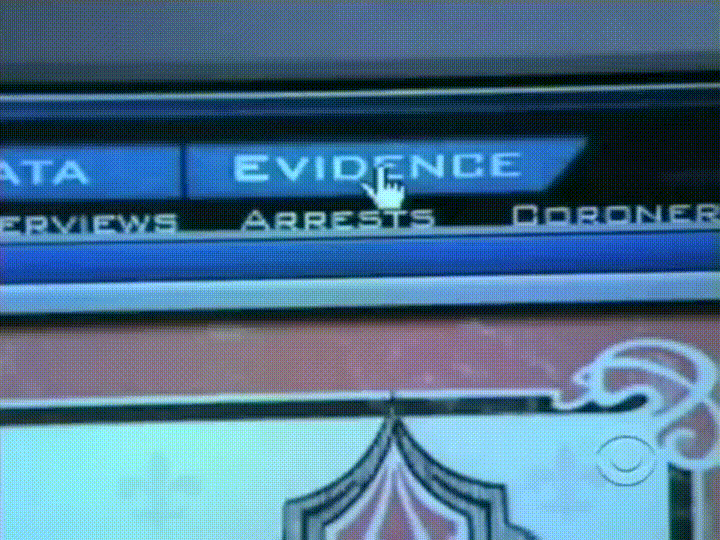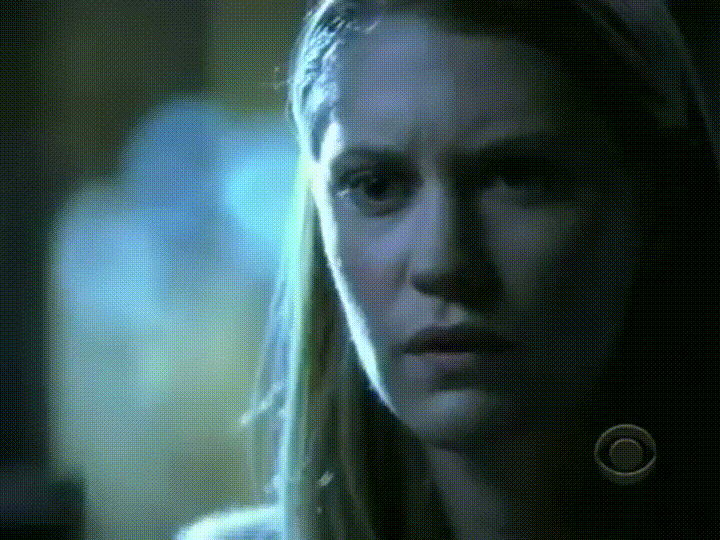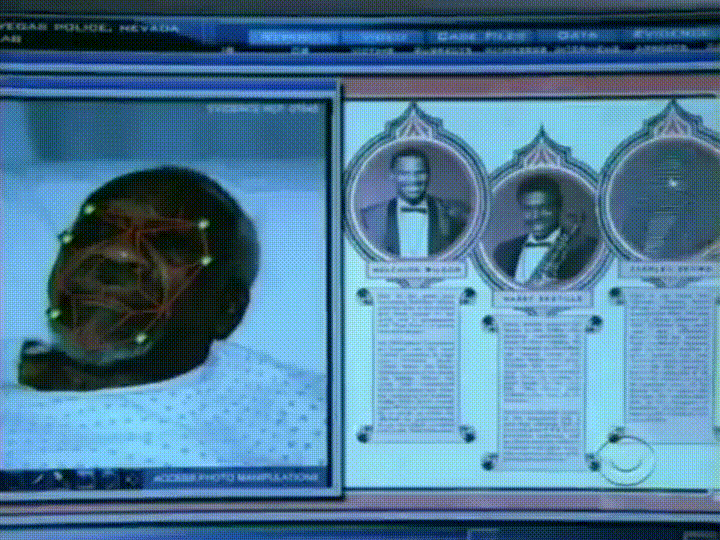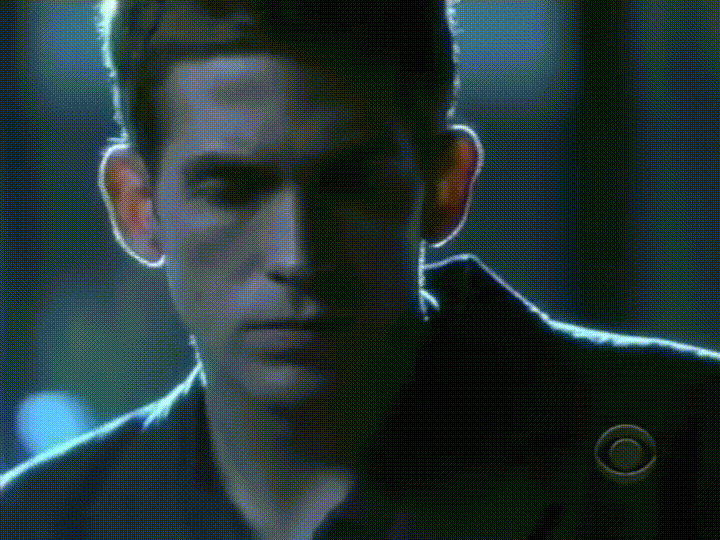
La forma más confiable de medir una cara
Ok, entonces, ¿qué medidas debemos recopilar de cada cara para construir nuestra base de datos de caras conocida? ¿Tamaño de oreja? ¿Longitud de nariz? ¿Color de ojos? Algo más?
Resulta que las medidas que nos parecen obvias a los humanos (como el color de los ojos) no tienen sentido para una computadora que mira píxeles individuales en una imagen. Los investigadores han descubierto que el enfoque más preciso es dejar que la computadora calcule las mediciones para recolectarse por sí misma. El aprendizaje profundo hace un mejor trabajo que los humanos para averiguar qué partes de un rostro son importantes medir.
La solución es entrenar una Red Neuronal Convolucional Profunda (como hicimos en la Parte 3). Pero en lugar de entrenar a la red para reconocer objetos de imágenes como lo hicimos la última vez, vamos a entrenarla para generar 128 medidas para cada cara.
El proceso de entrenamiento funciona mirando 3 imágenes de rostros a la vez:
- Cargar una imagen de rostro de entrenamiento de una persona conocida
- Cargar otra imagen de la misma persona conocida
- Cargar una imagen de una persona totalmente diferente
Luego el algoritmo mira las mediciones que está generando actualmente para cada una de esas tres imágenes. A continuación, retoca ligeramente la red neuronal para asegurarse de que las mediciones que genera para #1 y #2 estén un poco más cerca mientras se asegura de que las mediciones para #2 y #3 estén un poco más separadas:

Después de repetir este paso millones de veces para millones de imágenes de miles de personas diferentes, la red neuronal aprende a generar de manera confiable 128 mediciones para cada persona. Diez imágenes diferentes de la misma persona deben dar aproximadamente las mismas medidas.
Las personas de aprendizaje automático llaman incrustación a las 128 mediciones de cada cara. La idea de reducir datos crudos complicados como una imagen en una lista de números generados por computadora surge mucho en el aprendizaje automático (especialmente en la traducción de idiomas). El enfoque exacto para las caras que estamos utilizando fue inventado en 2015 por investigadores de Google, pero existen muchos enfoques similares.
Codificar nuestra imagen facial
Este proceso de entrenamiento de una red neuronal convolucional para generar incrustaciones faciales requiere una gran cantidad de datos y potencia de computadora. Incluso con una costosa tarjeta de vídeo NVidia Telsa, se necesitan unas 24 horas de formación continua para obtener una buena precisión.
Pero una vez que la red ha sido entrenada, puede generar mediciones para cualquier cara, ¡incluso para las que nunca ha visto antes! Así que este paso solo tiene que hacerse una vez. Por suerte para nosotros, la buena gente de OpenFace ya lo hizo y publicaron varias redes entrenadas que podemos usar directamente. Gracias Brandon Amos y equipo!
Así que todo lo que tenemos que hacer nosotros mismos es pasar nuestras imágenes faciales a través de su red preentrenada para obtener las 128 mediciones para cada cara. He aquí las mediciones para nuestra imagen de prueba:

Entonces, ¿qué partes de la cara son estos 128 números de medir exactamente? Resulta que no tenemos ni idea. En realidad no nos importa. Lo único que nos importa es que la red genere casi los mismos números al mirar dos imágenes diferentes de la misma persona.
Si desea probar este paso usted mismo, OpenFace proporciona un script lua que generará incrustaciones de todas las imágenes en una carpeta y las escribirá en un archivo csv. Lo haces así.
Paso 4: Encontrar el nombre de la persona desde la codificación
Este último paso es en realidad el paso más fácil de todo el proceso. Todo lo que tenemos que hacer es encontrar a la persona en nuestra base de datos de personas conocidas que tiene las mediciones más cercanas a nuestra imagen de prueba.
Puede hacerlo utilizando cualquier algoritmo básico de clasificación de aprendizaje automático. No se necesitan trucos sofisticados de aprendizaje profundo. Usaremos un clasificador SVM lineal simple, pero muchos algoritmos de clasificación podrían funcionar.
Todo lo que necesitamos hacer es entrenar a un clasificador que pueda tomar las mediciones de una nueva imagen de prueba y decir qué persona conocida es la más cercana. Ejecutar este clasificador toma milisegundos. El resultado del clasificador es el nombre de la persona!
Así que probemos nuestro sistema. Primero, entrené a un clasificador con las incrustaciones de unas 20 imágenes de Will Ferrell, Chad Smith y Jimmy Falon cada uno: