BasicsEdit
en Primer lugar, un poco de vocabulario:
| activación | = valor de estado de la neurona. Para las neuronas binarias, esto suele ser 0 / 1, o +1 / -1. |
| CAM | = contenido direccionable de memoria. Recordar una memoria mediante un patrón parcial en lugar de una dirección de memoria. |
| convergencia | = la estabilización de un patrón de activación en una red. En SL, convergencia significa estabilización de pesos & sesgos en lugar de activaciones. |
| discriminativo | = relacionado con tareas de reconocimiento. También se llama análisis (en Teoría de Patrones), o inferencia. |
| energía | = macroscópica cantidad de describir el patrón de activación en una red. (ver más abajo) |
| generalización | = comportarse de forma precisa previamente onu-encontrado entradas |
| generativo | = Máquina de imaginar y recordar la tarea. a veces se llama síntesis (en Teoría de Patrones), mímica o falsificaciones profundas. |
| inferencia | = la fase de» correr » (en contraposición al entrenamiento). Durante la inferencia, la red realiza la tarea para la que está entrenada, ya sea reconociendo un patrón (SL) o creando uno (UL). Generalmente inferencia desciende el gradiente de una función de energía. A diferencia del SL, el descenso de gradiente ocurre durante el entrenamiento, NO por inferencia. |
| visión artificial | = aprendizaje automático en imágenes. |
| PNL | = Procesamiento del Lenguaje Natural. Aprendizaje automático de lenguajes humanos. |
| pattern | = activaciones de red que tienen un orden interno en algún sentido, o que se pueden describir de forma más compacta por las características de las activaciones. Por ejemplo, el patrón de píxeles de un cero, ya sea dado como datos o imaginado por la red, tiene una característica que se puede describir como un bucle único. Las características están codificadas en las neuronas ocultas. |
| formación | = la fase de aprendizaje. Aquí, la red ajusta sus sesgos de ponderación & para aprender de las entradas. |
Tareas

Los métodos UL normalmente preparan una red para tareas generativas en lugar de reconocimiento, pero agrupar tareas como supervisadas o no puede ser confuso. Por ejemplo, el reconocimiento de escritura a mano comenzó en la década de 1980 como SL. Luego, en 2007, UL se utiliza para cebar la red para SL posteriormente. Actualmente, SL ha recuperado su posición como el mejor método.
Formación
Durante la fase de aprendizaje, una red sin supervisión intenta imitar los datos que se le proporcionan y utiliza el error en su salida mimetizada para corregirse a sí misma (p. ej. sus pesos & sesgos). Esto se asemeja al comportamiento de mimetismo de los niños mientras aprenden un idioma. A veces, el error se expresa como una baja probabilidad de que se produzca la salida errónea, o puede expresarse como un estado inestable de alta energía en la red.
Energía
Una función de energía es una medida macroscópica del estado de una red. Esta analogía con la física está inspirada en el análisis de Ludwig Boltzmann de la energía macroscópica de un gas a partir de las probabilidades microscópicas de movimiento de partículas p {{\displaystyle \propto }

eE/kT, donde k es la constante de Boltzmann y T es la temperatura. En la red RBM la relación es p = e-E / Z, donde p & E varía sobre cada patrón de activación posible y Z = ∑ A l l P a t t e r n s {\displaystyle \sum _{AllPatterns}}

e-E(patrón). Para ser más precisos, p(a) = e-E (a) / Z, donde a es un patrón de activación de todas las neuronas (visibles y ocultas). Por lo tanto, las primeras redes neuronales llevan el nombre de Máquina Boltzmann. Paul Smolensky llama a-E la Armonía. Una red busca baja energía que es alta Armonía.
Redes
| Hopfield | Boltzmann | gestión por resultados | Helmholtz | Autoencoder | VAE |
|---|---|---|---|---|---|
 |
 |
 restricted Boltzmann machine
|
 |
 autoencoder
|
 variacional autoencoder
|
Boltzmann y Helmholtz llegó antes de las redes neuronales formulaciones, pero estas redes prestado de su análisis, por lo que estas redes dan sus nombres. Hopfield, sin embargo, contribuyó directamente a UL.
IntermediateEdit
Aquí, las distribuciones p(x) y q(x) será abreviado como p y q.
History
| 1969 | Perceptrons by Minsky & Papert shows a perceptron without hidden layers fails on XOR |
| 1970s | (approximate dates) AI winter I |
| 1974 | Ising magnetic model proposed by WA Little for cognition |
| 1980 | Fukushima introduces the neocognitron, which is later called a convolution neural network. Se utiliza principalmente en SL, pero merece una mención aquí. |
| 1982 | Ising variant Hopfield net descrito como levas y clasificadores por John Hopfield. |
| 1983 | Máquina Boltzmann de variante Ising con neuronas probabilísticas descritas por Hinton & Sejnowski siguiendo a Sherington & El trabajo de Kirkpatrick de 1975. |
| 1986 | Paul Smolensky publica la Teoría de la Armonía, que es un RBM con prácticamente la misma función de energía de Boltzmann. Smolensky no dio un plan de entrenamiento práctico. Hinton lo hizo a mediados de la década de 2000 |
| 1995 | Schmidthuber introduce la neurona LSTM para lenguajes. |
| 1995 | Dayan & Hinton introduces Helmholtz machine |
| 1995-2005 | (approximate dates) AI winter II |
| 2013 | Kingma, Rezende, & co. introduced Variational Autoencoders as Bayesian graphical probability network, with neural nets as components. |
Some more vocabulary:
| Probabilidad | |
| cdf | = función de distribución acumulativa. la integral del pdf. La probabilidad de acercarse a 3 es el área bajo la curva entre 2.9 y 3.1. |
| divergencia contrastiva | = un método de aprendizaje en el que se reduce la energía en los patrones de entrenamiento y aumenta la energía en los patrones no deseados fuera del conjunto de entrenamiento. Esto es muy diferente de la divergencia KL, pero comparte una redacción similar. |
| valor esperado | = E(x) = ∑ x {\displaystyle \sum _{x}}
 x * p(x). Este es el valor medio, o valor medio. Para la entrada continua x, reemplace la suma con una integral. |
| variable latente | = un inadvertido cantidad que ayuda a explicar los datos observados. por ejemplo, una infección de gripe (no observada) puede explicar por qué la persona estornuda (observada). En las redes neuronales probabilísticas, las neuronas ocultas actúan como variables latentes, aunque su interpretación latente no se conoce explícitamente. |
| = función de densidad de probabilidad. La probabilidad de que una variable aleatoria tome un cierto valor. Para pdf continuo, p ( 3) = 1/2 todavía puede significar que hay casi cero posibilidades de lograr este valor exacto de 3. Racionalizamos esto con la cdf. | |
| estocástico | = se comporta de acuerdo con una fórmula de densidad de probabilidad bien descrita. |
| Thermodynamics | |
| Boltzmann distribution | = Gibbs distribution. p ∝ {\displaystyle \propto }
eE/kT |
| entropy | = expected information = ∑ x {\displaystyle \sum _{x}}
p * log p |
| Gibbs free energy | = thermodynamic potential. Es el trabajo reversible máximo que puede realizar un sistema de calor a temperatura y presión constantes. la energía libre G = calor – temperatura * la entropía |
| información | = la cantidad de información de un mensaje x = -log p(x) |
| KLD | = relación de la entropía. Para redes probabilísticas, este es el análogo del error entre la salida imitada input &. La divergencia Kullback-Liebler (KLD) mide la desviación de entropía de 1 distribución de otra distribución. KLD( p, q) = ∑ x {\displaystyle \sum _{x}}
p * log (p / q ). Por lo general, p refleja los datos de entrada, q refleja la interpretación de la red y KLD refleja la diferencia entre los dos. |
la Comparación de Redes
| Hopfield | Boltzmann | gestión por resultados | Helmholtz | Autoencoder | VAE | |
|---|---|---|---|---|---|---|
| uso & personajes | CAM, problema del viajante de comercio | CAM. La libertad de conexiones hace que esta red sea difícil de analizar. | reconocimiento de patrones (MNIST, reconocimiento de voz) | imaginación, mimetismo | lenguaje: escritura creativa, traducción. Vision: mejora de imágenes borrosas | generar datos realistas |
| neurona | determinista binario estado. Activation = { 0 (o -1) si x es negativo, 1 de lo contrario } | neurona hopfield binaria estocástica | binario estocástico. Extendido a valores reales a mediados de la década de 2000 | binario, sigmoide | lenguaje: LSTM. visión: campos receptivos locales. usualmente real valorados relu de activación. | |
| conexiones | 1-capa con simétrica pesos. Sin auto-conexiones. | 2-capas. 1-oculto & 1-visible. pesos simétricos. | 2-capas. pesos simétricos. sin conexiones laterales dentro de una capa. | 3 capas: pesos asimétricos. 2 redes combinadas en 1. | 3-capas. La entrada se considera una capa a pesar de que no tiene pesos de entrada. capas recurrentes para PNL. circunvoluciones de alimentación para visión. input & la salida tiene el mismo recuento de neuronas. | 3 capas: entrada, codificador, decodificador de sampler de distribución. el muestreador no se considera una capa (e) |
| inferencia & energía | la energía viene dada por la medida de probabilidad de Gibbs : E = − 1 2 ∑ i , j w i j s i s j + ∑ i θ i s i {\displaystyle E=-{\frac {1}{2}}\sum _{i,j}{w_{ij}{s_{i}}{s_{j}}}+\sum _{i}{\theta _{i}}{s_{i}}}
 |
← mismo | ← mismo | minimizar la divergencia KL | inferencia es sólo feed-forward. las redes UL anteriores corrían hacia adelante y hacia atrás | minimizar error = error de reconstrucción-KLD |
| entrenamiento | Δwij = si*sj, para +1/-1 neurona | Δwij = e*(pij – p’ij). Esto se deriva de minimizar KLD. e = tasa de aprendizaje, p ‘ = distribución prevista y p = distribución real. | divergencia contrastiva con muestreo de Gibbs | entrenamiento de 2 fases de vigilia-sueño | propagar el error de reconstrucción | reparameterizar el estado oculto para la protección trasera |
| fuerza | se asemeja a los sistemas físicos, por lo que hereda sus ecuaciones | <— lo mismo. las neuronas ocultas actúan como representación interna del mundo externo | esquema de entrenamiento más rápido y práctico que las máquinas Boltzmann | ligeramente anatómicas. analizable w/ teoría de la información & mecánica estadística | ||
| debilidad | hopfield | duro para entrenar debido a las conexiones laterales | gestión por resultados | Helmholtz |
Redes Específicas
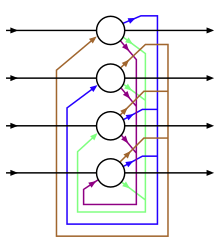
en este sentido, destacamos algunas de las características de cada una de las redes. El ferromagnetismo inspiró a Hopfield networks, Boltzmann machines y RBMs. Una neurona corresponde a un dominio de hierro con momentos magnéticos binarios Arriba y Abajo, y las conexiones neuronales corresponden a la influencia del dominio entre sí. Las conexiones simétricas permiten una formulación de energía global. Durante la inferencia, la red actualiza cada estado utilizando la función de paso de activación estándar. Los pesos simétricos garantizan la convergencia a un patrón de activación estable.
Las redes Hopfield se utilizan como levas y se garantiza que se ajustan a un cierto patrón. Sin pesos simétricos, la red es muy difícil de analizar. Con la función de energía adecuada, una red convergerá.
Las máquinas Boltzmann son redes estocásticas de lúpulo. Su valor de estado se muestra de este pdf de la siguiente manera: supongamos que una neurona binaria se dispara con la probabilidad de Bernoulli p(1) = 1/3 y descansa con p(0) = 2/3. Una muestra de ella tomando un número aleatorio distribuido uniformemente y, y conectándolo a la función de distribución acumulada invertida, que en este caso es la función escalonada con un umbral de 2/3. La función inversa = {0 if x < = 2/3, 1 if x > 2/3 }
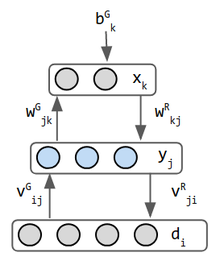
Las máquinas Helmholtz son las primeras inspiraciones para los Codificadores automáticos Variacionales. Sus 2 redes combinadas en pesas de un solo avance operan el reconocimiento y las pesas de retroceso implementan la imaginación. Es quizás la primera red que hace ambas cosas. Helmholtz no trabajó en el aprendizaje automático, pero inspiró la visión del «motor de inferencia estadística cuya función es inferir las causas probables de la entrada sensorial» (3). la neurona binaria estocástica genera una probabilidad de que su estado sea 0 o 1. La entrada de datos normalmente no se considera una capa, pero en el modo de generación de máquinas de Helmholtz, la capa de datos recibe la entrada de la capa intermedia con pesos separados para este propósito, por lo que se considera una capa. Por lo tanto, esta red tiene 3 capas.El Autoencoder variacional (VAE) está inspirado en máquinas Helmholtz y combina redes de probabilidad con redes neuronales. Un Autoencoder es una red CAM de 3 capas, donde se supone que la capa intermedia es una representación interna de patrones de entrada. Los pesos se denominan phi & theta en lugar de W y V como en Helmholtz, una diferencia cosmética. La red neuronal codificadora es una distribución de probabilidad qφ (z / x) y la red decodificadora es pθ(x|z). Estas 2 redes aquí pueden estar completamente conectadas, o usar otro esquema NN.
Aprendizaje Hebbiano, ARTE, SOM
El ejemplo clásico de aprendizaje no supervisado en el estudio de las redes neuronales es el principio de Donald Hebb, es decir, las neuronas que se activan juntas se conectan entre sí. En el aprendizaje hebbiano, la conexión se refuerza independientemente de un error, pero es exclusivamente una función de la coincidencia entre los potenciales de acción entre las dos neuronas. Una versión similar que modifica los pesos sinápticos tiene en cuenta el tiempo entre los potenciales de acción (plasticidad dependiente del tiempo de pico o STDP). Se ha planteado la hipótesis de que el aprendizaje hebbiano es la base de una serie de funciones cognitivas, como el reconocimiento de patrones y el aprendizaje experiencial.
Entre los modelos de redes neuronales, el mapa autoorganizado (SOM) y la teoría de resonancia adaptativa (ART) se utilizan comúnmente en algoritmos de aprendizaje no supervisados. El SOM es una organización topográfica en la que las ubicaciones cercanas en el mapa representan entradas con propiedades similares. El modelo ART permite que el número de clústeres varíe con el tamaño del problema y permite al usuario controlar el grado de similitud entre los miembros de los mismos clústeres mediante una constante definida por el usuario llamada parámetro vigilance. Las redes ART se utilizan para muchas tareas de reconocimiento de patrones, como el reconocimiento automático de objetivos y el procesamiento de señales sísmicas.