Todos los usuarios de bases de datos conocen las funciones agregadas regulares que operan en una tabla completa y se utilizan con una cláusula GROUP BY. Pero muy pocas personas usan funciones de ventana en SQL. Estos operan en un conjunto de filas y devuelven un único valor agregado para cada fila.
La principal ventaja de usar funciones de ventana sobre funciones de agregado regulares es: Las funciones de ventana no hacen que las filas se agrupen en una sola fila de salida, las filas conservan sus identidades separadas y se agregará un valor agregado a cada fila.
Echemos un vistazo a cómo funcionan las funciones de ventana y luego veamos algunos ejemplos de cómo se usan en la práctica para asegurarnos de que las cosas están claras y también cómo se comparan el SQL y la salida con el de las funciones SUM ().
Como siempre, asegúrese de tener una copia de seguridad completa, especialmente si está probando cosas nuevas con su base de datos.
Introducción a las funciones de ventana
Las funciones de ventana operan en un conjunto de filas y devuelven un único valor agregado para cada fila. La Ventana de términos describe el conjunto de filas de la base de datos en las que operará la función.
Definimos la Ventana (conjunto de filas en las que opera functions) usando una cláusula OVER (). Discutiremos más sobre la cláusula OVER () en el artículo a continuación.
Types of Window functions
Syntax
|
1
2
3
4
|
window_function ( expression )
OVER ( )
|
Arguments
window_function
Specify the name of the window function
ALL
ALL is an optional keyword. Cuando incluya TODO, contará todos los valores, incluidos los duplicados. DISTINCT no es compatible con funciones de ventana
expresión
La columna o expresión de destino en la que operan las funciones. En otras palabras, el nombre de la columna para la que necesitamos un valor agregado. Por ejemplo, una columna que contiene el importe del pedido para que podamos ver el total de pedidos recibidos.
SOBRE
Especifica las cláusulas de ventana para funciones agregadas.
PARTITION BY partition_list
Define la ventana (conjunto de filas en las que opera la función de ventana) para las funciones de ventana. Necesitamos proporcionar un campo o una lista de campos para la cláusula partición tras PARTICIÓN BY. Los campos múltiples deben estar separados por una coma, como de costumbre. Si no se especifica la PARTICIÓN BY, la agrupación se realizará en toda la tabla y los valores se agregarán en consecuencia.
ORDER BY order_list
Ordena las filas dentro de cada partición. Si no se especifica ORDER BY, ORDER BY utiliza toda la tabla.
Ejemplos
Vamos a crear tablas e insertar registros ficticios para escribir más consultas. Corre por debajo del código.
Funciones de ventana agregadas
SUM ()
Todos conocemos la función agregada SUM (). Hace la suma del campo especificado para el grupo especificado (como ciudad, estado, país, etc.).) o para toda la tabla si no se especifica el grupo. Veremos cuál será la salida de la función de agregado SUM() regular y la función de agregado SUM() window.
El siguiente es un ejemplo de una función de agregado SUM() regular. Suma el importe del pedido para cada ciudad.
Puede ver en el conjunto de resultados que una función de agregado regular agrupa varias filas en una sola fila de salida, lo que hace que las filas individuales pierdan su identidad.
|
1
2
3
4
|
SELECCIONE la ciudad, SUM(order_amount) total_order_amount
DE . GRUPO de la ciudad
|

Esto no sucede con la ventana de funciones de agregado. Las filas conservan su identidad y también muestran un valor agregado para cada fila. En el ejemplo a continuación, la consulta hace lo mismo, es decir, agrega los datos para cada ciudad y muestra la suma del monto total del pedido para cada una de ellas. Sin embargo, la consulta ahora inserta otra columna para el importe total del pedido, de modo que cada fila conserve su identidad. La columna marcada grand_total es la nueva columna en el siguiente ejemplo.
AVG()
AVG o Promedio funciona exactamente de la misma manera con una función de Ventana.
La siguiente consulta le dará el monto promedio del pedido para cada ciudad y para cada mes (aunque para simplificar, solo hemos utilizado datos en un mes).
Especificamos más de un promedio especificando varios campos en la lista de particiones.
También vale la pena señalar que puede usar expresiones en las listas como MONTH (order_date) como se muestra en la siguiente consulta. Como siempre, puede hacer que estas expresiones sean tan complejas como desee, siempre y cuando la sintaxis sea correcta.
De la imagen de arriba, podemos ver claramente que en promedio hemos recibido pedidos de 12,333 para Arlington city para abril de 2017.
Cantidad de Pedido promedio = Cantidad de Pedido Total / Pedidos Totales
= (20,000 + 15,000 + 2,000) / 3
= 12,333
También puede usar la combinación de la función SUM() & COUNT() para calcular un promedio.
MIN ()
La función de agregado MIN () encontrará el valor mínimo para un grupo especificado o para toda la tabla si el grupo no está especificado.
Por ejemplo, estamos buscando el orden más pequeño (orden mínimo) para cada ciudad, usaríamos la siguiente consulta.
MAX ()
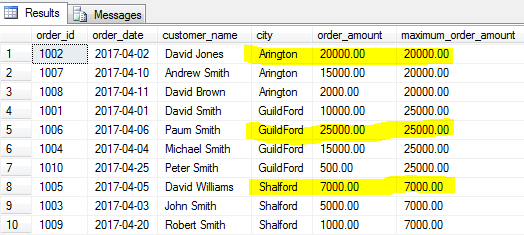
Al igual que las funciones MIN () le dan el valor mínimo, la función MAX () identificará el valor más grande de un campo especificado para un grupo de filas especificado o para toda la tabla si no se especifica un grupo.
vamos a encontrar el pedido más grande (cantidad máxima de pedido) para cada ciudad.
COUNT()
COUNT() función contar los registros o filas.
Tenga en cuenta que DISTINCT no es compatible con la función window COUNT (), mientras que es compatible con la función COUNT() regular. DISTINCT le ayuda a encontrar los valores distintos de un campo especificado.
Por ejemplo, si queremos ver cuántos clientes han realizado un pedido en abril de 2017, no podemos contar directamente a todos los clientes. Es posible que el mismo cliente haya realizado varios pedidos en el mismo mes.
COUNT(customer_name) le dará un resultado incorrecto ya que contará duplicados. Mientras que COUNT (customer_name DISTINTO) le dará el resultado correcto, ya que cuenta cada cliente único solo una vez.
Válido para la función regular COUNT() :
|
1
2
3
4
5
|
SELECCIONE la ciudad,COUNT(DISTINCT customer_name) number_of_customers
DE .
AGRUPAR POR ciudad
|
No válido para la función window COUNT ():
La consulta anterior con la función Window le dará el error siguiente.
Ahora, vamos a encontrar el pedido total recibido para cada ciudad usando la función window COUNT ().
Funciones de ventana de clasificación
Al igual que las funciones de agregado de ventana agregan el valor de un campo especificado, las funciones de clasificación clasificarán los valores de un campo especificado y los categorizarán de acuerdo con su rango.
El uso más común de las funciones de CLASIFICACIÓN es encontrar los registros superiores (N) basados en un cierto valor. Por ejemplo, los 10 empleados mejor pagados, los 10 estudiantes mejor clasificados, los 50 pedidos más grandes, etc.
Las siguientes son funciones de CLASIFICACIÓN soportadas:
RANK(), DENSE_RANK(), ROW_NUMBER(), NTILE ()
Vamos a discutirlas una por una.
RANK ()
La función RANK () se utiliza para dar un rango único a cada registro basado en un valor especificado, por ejemplo, salario, cantidad de pedido, etc.
Si dos registros tienen el mismo valor, la función RANK () asignará el mismo rango a ambos registros omitiendo el siguiente rango. Esto significa que si hay dos valores idénticos en el rango 2, asignará el mismo rango 2 a ambos registros y luego saltará el rango 3 y asignará el rango 4 al siguiente registro.
Clasifiquemos cada pedido por su cantidad de pedido.
|
1
2
3
4
5
|
SELECCIONE id_pedido,order_date,customer_name,la ciudad, el
RANK() OVER(ORDER BY order_amount DESC)
DE .
|
En la imagen de arriba, puede ver que el mismo rango (3) está asignado a dos registros idénticos (cada uno con un monto de pedido de 15,000) y luego salta el siguiente rango (4) y asigna el rango 5 al siguiente registro.
DENSE_RANK ()
La función DENSE_RANK() es idéntica a la función RANK () excepto que no omite ningún rango. Esto significa que si se encuentran dos registros idénticos, DENSE_RANK () asignará el mismo rango a ambos registros, pero no saltará, y luego saltará el siguiente rango.
Veamos cómo funciona esto en la práctica.
Como puede ver claramente arriba, se da el mismo rango a dos registros idénticos (cada uno con la misma cantidad de pedido) y luego se da el siguiente número de rango al siguiente registro sin omitir un valor de rango.
ROW_NUMBER()
El nombre es auto-explicativo. Estas funciones asignan un número de fila único a cada registro.
El número de fila se restablecerá para cada partición si se especifica PARTICIÓN BY. Veamos cómo funciona ROW_NUMBER () sin PARTICIÓN BY y luego con PARTICIÓN BY.
ROW_ NÚMERO() sin PARTICIÓN
ROW_NUMBER() con la PARTICIÓN
tenga en cuenta que hemos hecho la partición en la ciudad. Esto significa que el número de fila se restablece para cada ciudad y, por lo tanto, se reinicia en 1 de nuevo. Sin embargo, el orden de las filas está determinado por la cantidad de la orden, de modo que para cualquier ciudad, la cantidad de orden más grande será la primera fila y, por lo tanto, se le asignará el número de fila 1.
NTILE ()
NTILE() es una función de ventana muy útil. Le ayuda a identificar en qué percentil (o cuartil, o cualquier otra subdivisión) cae una fila dada.
Esto significa que si tiene 100 filas y desea crear 4 cuartiles basados en un campo de valor especificado, puede hacerlo fácilmente y ver cuántas filas caen en cada cuartil.
Veamos un ejemplo. En la consulta a continuación, hemos especificado que queremos crear cuatro cuartiles basados en la cantidad del pedido. Luego queremos ver cuántos pedidos caen en cada cuartil.
NTILE crea azulejos basado en la siguiente fórmula:
No de filas en cada mosaico = número de filas en el conjunto de resultados / número de mosaicos especificados
Este es nuestro ejemplo, tenemos un total de 10 filas y se especifican 4 mosaicos en la consulta, por lo que el número de filas en cada mosaico será 2.5 (10/4). Como el número de filas debe ser un número entero, no un decimal. El motor SQL asignará 3 filas para los dos primeros grupos y 2 filas para los dos grupos restantes.
Funciones de ventana de valores
LAG () y LEAD ()
Las funciones LEAD () y LAG () son muy potentes pero pueden ser complejas de explicar.
Como este es un artículo introductorio a continuación, estamos viendo un ejemplo muy simple para ilustrar cómo usarlos.
La función LAG permite acceder a los datos de la fila anterior en el mismo conjunto de resultados sin usar ninguna unión SQL. Puedes ver en el siguiente ejemplo, usando la función de RETRASO encontramos la fecha de pedido anterior.
Script para encontrar la fecha de pedido anterior utilizando la función LAG ():
La función LEAD permite acceder a los datos de la siguiente fila en el mismo conjunto de resultados sin usar ninguna unión SQL. Puede ver en el siguiente ejemplo, usando la función de PLOMO encontramos la siguiente fecha de pedido.
Script para encontrar la fecha del siguiente orden usando la función LEAD ():
FIRST_VALUE () y LAST_VALUE ()
Estas funciones le ayudan a identificar el primer y el último registro dentro de una partición o tabla completa si no se especifica la PARTICIÓN BY.
Busquemos el primer y el último orden de cada ciudad de nuestro conjunto de datos existente. Nota La cláusula ORDER BY es obligatoria para las funciones FIRST_VALUE() y LAST_VALUE ()
En la imagen de arriba, podemos ver claramente que el primer pedido recibido el 2017-04-02 y el último pedido recibido el 2017-04-11 para Arlington city y funciona igual para otras ciudades.
Enlaces útiles
- Tipos de copia de seguridad & Estrategias para bases de datos SQL
- Artículo de TechNet sobre la Cláusula OVER
- Artículo de MSDN Sobre DENSE_RANK
Otros excelentes artículos de Ben
Cómo selecciona SQL Server una víctima de bloqueo
Cómo Para usar las Funciones de ventana
- Autor
- Publicaciones recientes
Ver todas las publicaciones de Ben Richardson
- Power BI: Gráficos en cascada y Visuales combinados – 19 de enero de 2021
- Poder BI: El formato condicional y los datos de los colores en la acción – 14 de enero de 2021
- Potencia BI: Importación de datos de SQL Server y MySQL – 12 de enero de 2021